
1矩阵向量乘法(4分)
讲义55页所示结果Y,如果要作为下一次矩阵向量乘法的输入X,切分到不同的列进程,并且复制到每一行进程,应如何操作?可写出伪代码,或用语言描述。
即图(a)中的Y,变成下图(b)中的X。假设每行有P个进程,每列也是P个进程,一共P*P个进程。
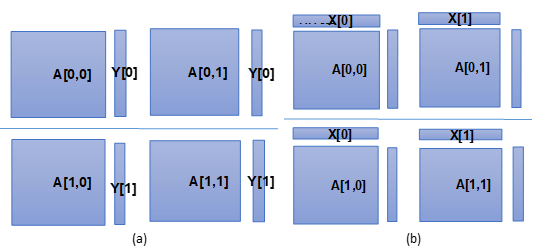
答:进程$P_{ij}$和所控制的矩阵进行矩阵向量乘之后,将结果存入进程$P_{ji}$。
2 代码填空(3分)
在测量程序性能时,我们经常要记录整个程序或程序中某一部分的运行时间。在MPI程序中,由于每个进程的运行时间不同,一般需要取各个进程运行时间的最大值,然后由0号进程保存和打印(其他进程不需要保存)。以下程序完成了这个功能,请在横线处填上函数调用语句。
int main(int argc, char * argv) {
double total_time;
double time0, time1;
int procs, rank;
MPI_init(argc, argv);
MPI_Comm_size(MPI_COMM_WORLD, &procs);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
time0 = MPI_Wtime();
//do some computation
time1 = MPI_Wtime() – time0;
_______________________________________________________________
if(rank == 0) {
Printf(“Total execution time is %f seconds\n”, total_time);
}
}
答:
MPI_Reduce(&time1,&total_time,1,MPI_DOUBLE,MPI_MAX,0,MPI_COMM_WORLD)
3 以下程序相当于哪个MPI聚合操作?(3分)
#define N 16384
double *send_buff, *recv_buff;
MPI_Status status;
int i, nprocs, myid, count=N/num_procs;
send_buff = (double*)malloc(N*sizeof(double));
recv_buff = (double*)malloc(N*sizeof(double));
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
//此处省略send_buff中数据的初始化
memcpy((void*)(recv_buff + myid * count), (void*)(send_buff + myid * count), count*sizeof(double));
for(int i = 0; i < nprocs;i++) {
if(i!=myid) {
MPI_Sendrecv(send_buff+i*count, count, MPI_DOUBLE, i, 400, recv_buff+i*count, count, MPI_DOUBLE, i, 400, MPI_COMM_WORLD, &status);
}
}
答:MPI_Alltoall()