
《AntMan: Dynamic Scaling on GPU Clusters for Deep Learning》论文阅读笔记
Abstract
如何在大规模GPU集群上有效调度深度学习工作, 对于工作性能,系统吞吐量和硬件利用率至关重要。
- 随着深度学习的工作量变得更加复杂,它变得越来越具有挑战性。
本文将介绍Antman, 这是一种深入学习的基础设施,该基础架构共同设计了集群调度程序,并已在阿里巴巴部署在生产中,以管理数以万计的每日深度学习工作。
- Antman适应深度学习训练的波动资源需求。因此,它利用备用GPU资源在共享GPU上共同执行多个作业。
- Antman利用深度学习训练的独特特征,在深度学习框架内为显存和计算资源引入动态缩放机制。这允许job之间的细粒度协调并防止工作干扰。
- 评估表明,Antman在我们的多租户集群中不损害公平性的情况下,整体将显存利用率提高了42%,计算资源利用率提高了34%,为有效利用大规模的GPU提出了新方法。
Introduction
- 在共享多租户的DL集群, 许多工作排队等待资源的时候会导致GPU利用率低下,有两个原因
- 大多数的训练任务在执行过程中不能完全利用GPU资源
- 训练一个DL模型通常需要多种计算的混合
- 当使用分布式的训练的时候,90%的时间会被浪费到网络通信上
- 基于资源预留的集群调度方案导致显著的GPU空闲,DL工作中总有部分资源没有投入使用
- 例如,随机梯度下降是同步的,需要获取所有的资源以进行gang-scheduling, 在得到所有资源之前,已得到的部分资源就会陷入空闲
- 大多数的训练任务在执行过程中不能完全利用GPU资源
- 在共享GPU上进行packing job
- 可以提高GPU的利用率,可以使得同样的集群整体上胜任更多的job。
- 但是这个策略在生产集群上很少使用, 原因
- 尽管提升GPU的利用率是有利的,但也要保证resource-guarantee jobs(RGJ,资源保证性job)的性能。同一个GPU上同时执行多个job会导致干扰–>RGJ性能出现显著下降
- job packing策略可以给并发job引入内存竞争。job需要的资源陡然增加的话,有可能导致训练任务failure。
- 因此,job资源的独占分配在显存的GPU集群生产环境中比较典型
- 我们提出AntMan
- 简述
- 一个DL系统提高GPU集群的利用率
- 同时保证公平性与RGJ的性能
- 通过合作性的资源扩缩来减少job干扰
- DL系统中引入了新的分配机制在job训练过程中来动态地精确分配所需资源(显存和计算单元)
- 使用超卖机制使得任何空闲的GPU资源(显存和计算单元)都能被利用
- 重新设计了集群调度器和DL框架来适应生产job的波动的资源特点
- 通过
- 框架信息感知调度
- 透明显存扩展
- 快速可持续的任务间协调
- 使用这个结构,Antman为DL任务的同时执行的policy design 开辟了空间
- 通过
- AntMan采用了简单且有效的策略来最大化集群吞吐
- 为RGJ提供资源保证的同时
- 分配一些偶然性的任务来尽力而为的利用GPU资源(低优先级且不保证资源)
- 简述
- 本文主要贡献如下
- 对生产环境的DL集群进行调研,发现低利用率来自于三个方面:硬件,集群调度,job行为
- 在DL框架中为显存和计算单元管理引入了两种动态放缩机制,来解决GPU共享问题。新机制利用DL的工作特征来动态调整DL job的资源使用情况,在作业执行期间。
- 通过共同设计集群调度器和DL框架以利用动态缩放机制,我们为GPU共享引入了一种新的工业方法。这在多租户集群中维护工作服务级协议(SLA),同时通过机会调度来改善集群利用率。
- 在超过5000个GPU上进行了实验
Motivation
deep learning Training
- 深度学习训练通常包括数百万次迭代,每个迭代过程都称为mini-batch。
- 通常,训练mini-batch可以分为三个阶段。
- 首先,计算样品和模型权重以产生一组得分,称为forward pass
- 其次,使用目标函数在产生的分数和所需的分数之间计算loss error。然后,损失通过模型向后扩散,以计算梯度,称为backward pass。
- 最后,通过由优化器定义的学习率来缩放梯度,以更新模型参数。
- 正向通行的计算输出通常包括许多数据输出,每个数据输出称为张量。这些张量应暂时保存在内存中,并被向后通过以计算梯度。通常,为了监视培训中的模型质量,定期触发评估.
- 通常,训练mini-batch可以分为三个阶段。
- 为了使用大量数据培训模型,DL通常在多个GPU中采用数据并行性,其中每个GPU负责并行处理数据子集,同时在模型更新之前执行每个迷你批次梯度同步。
- 在大型公司中,多租户集群通常用于改善硬件利用率,用户有时可以超额订阅GPU资源配额,尤其是当GPU要求爆发时。
Characterizing Production DL Cluster
我们从三个角度研究生产集群中的资源使用率:硬件,集群调度和job行为。
在使用中的GPU的低利用率
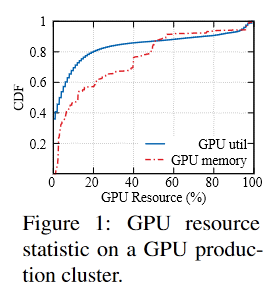
image-20220831200958715 - 内存容量。如图所示,只有20%的GPU正在运行消耗一半以上GPU存储器的应用程序。
- 关于计算单元的使用,只有10%的GPU获得了高于80%的GPU利用率。
- 该统计数据表明,GPU内存和计算单元均未得到充分利用,因此浪费了昂贵的硬件资源。
对gang-schedule的空闲等待
Gang scheduling是在并发系统中将多个相关联的进程调度到不同处理器上同时运行的策略,其最主要的原则是保证所有相关联的进程能够同时启动,防止部分进程的异常,导致整个关联进程组的阻塞。例如,您提交一个批量Job,这个批量Job包含多个任务,要么这多个任务全部调度成功,要么一个都调度不成功。这种All-or-Nothing调度场景,就被称作Gang scheduling。
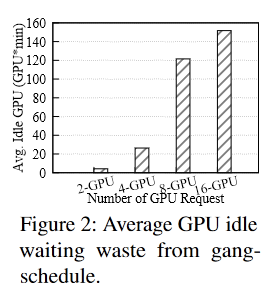
image-20220831201015900 - 多GPU训练工作需要Gang scheduling,这意味着除非同时提供所有必需的GPU,否则job将不会开始训练
- 由于GPU资源往往不能同时全部获得, 所以会出现idle waiting。 一个job需要的GPU越多, 它的平均闲置时间就越长
- **资源到达的不可预测导致了预留资源的idle waiting。**一个幼稚的解决方案是在GPU idle waiting的时候执行别的job。但是这会导致资源需求大job的饥饿,影响分配公平性。另外一旦资源需要被满足导致的GPU需求激增或许导致GPU之间的资源冲突,导致工作fail
动态资源需求
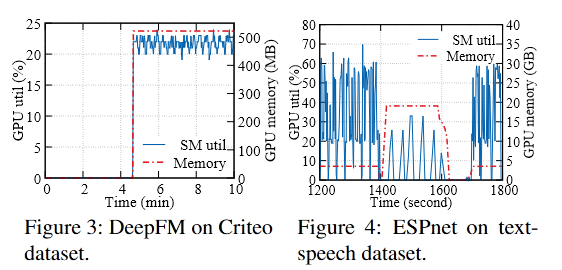
image-20220831201047910 - 在一个DL job生命周期中, GPU资源往往未被充分利用。
- 图3:在Criteo数据集上运行DEEPFM [20]时的前10分钟。一开始,数据集上的预处理仅需要CPU。但是,GPU的SM利用率和内存使用量在275秒时启动。
- 图4:训练可以包含几个阶段,不同阶段的SM和Memory的使用率都是不一样的
- 资源需求的动态变化与固定的资源分配和漫长的训练时间相矛盾。资源需要满足job的峰值需要,导致这个昂贵的硬件被低效利用。显存的DL框架的memory caching设计隐藏了显存使用随时间的变化,一定程度上阻止了GPU的潜在共享。
Opportunities in DL Uniqueness
超卖有机会提高集群的吞吐
- 不可预测的job内和job间的需求激增为安全的资源共享引入了挑战
- 因为资源竞争, jobs可能会把显存用光
- 在多租户集群中,当jobs在共享环境执行时,为持有定额资源的job提供性能隔离是十分重要的
- AntMan利用DL training的特性来利用这个机会
- 不可预测的job内和job间的需求激增为安全的资源共享引入了挑战
我们在生产环境集群的10k个task中取样发现
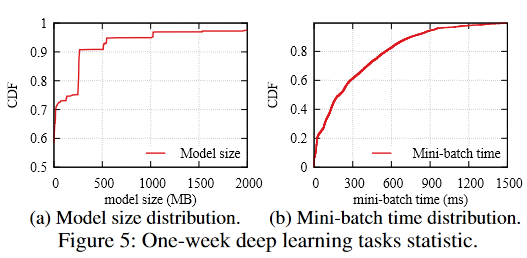
image-20220905143619325 - 只有一小部分用来存储模型, 且90%的模型大小不超过500M
- 大部分显存在同一个mini-batch中被分配和释放
- 除此之外,一个mini-batch的消耗时间很短, 80%的任务在600ms之内消耗一个mini-batch
我们通过多种方式利用这种独特的特征来安排共享GPU上的作业。
- 首先,根据通常的模型大小,大部分显存在共同执行的作业中可以拿来调度
- 其次,mini-batch的周期通常很短,可以在每个mini-batch边界处进行细粒度的GPU内存和计算资源的调度。这可以进一步允许job间的快速资源协调。
- 第三,mini-batch通常进行相似的计算,这可以被利用去描述job性能,因此进度率可以被创建作为性能矩阵来量化干扰。
Design
AntMan深入共同设计集群调度程序和DL框架, 本部分将介绍三部分:DL 框架的修改,调度器与调度原则
Dynamic Scaling in DL Frameworks
- 低使用效率的GPU集群有着执行更多任务的潜力,但需要解决一下挑战
- 使用最下需求执行job的同时防止GPU内存使用的爆发导致的失效
- 适应计算单元的使用波动的同时限制潜在的干扰
- DL框架是专注于GPU执行, 缺乏job合作的能力。这激发了动态缩放机制的设计,机制包含内存和计算两部分
Memory Management
AntMan以tensor为单位,在GPU和CPU的内存间进行动态内存管理。类似于操作系统的虚拟内存,AntMan以tensor为单位进行了显存虚拟化,通过这种方式,DL框架可以提供超出上限的显存。
显存分配
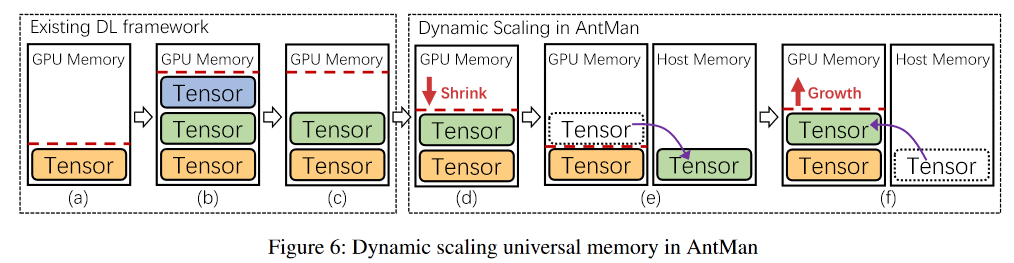
image-20220905151151692 - 在张量被销毁后,GPU内存被缓存在DL框架内的一个全局内存分配器中,普遍情况下,一些张量只在DL训练的某些阶段使用(如数据预处理、评估),不再需要了。然而,这部分缓存的GPU内存不会被释放(图6c)。DL框架中的这种缓存内存设计优化了单个作业的性能,但代价是失去了共享潜力。
- AntMan转向了扩展GPU内存上限的方法。它主动检测使用中的内存,以缩小缓存的内存,从而自省地将GPU内存的使用调整合适。这是通过监测应用性能和处理小批量时的内存需求来实现的(图6d)。AntMan使用其最大的努力在GPU设备上分配张量,然而,如果GPU内存仍然缺乏,张量可以在GPU之外用主机内存分配(图6e)。当GPU内存的上限增加时,Tensors可以自动分配回GPU(图6f)。
显存上限动态调整
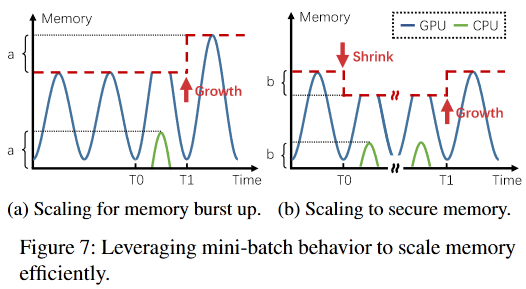
image-20220905151235705 图7a说明了内存扩展如何解决突发需求。在T0,正在运行的DL训练作业的内存需求增加,由于GPU内存的有限上限,一些张量不能放在GPU内存中,而是使用主机内存创建。AntMan检测到主机内存的使用情况,在T1,它根据主机内存的使用情况提高该作业的GPU内存的上限,虽然在这一个小批次中,这个运行作业的性能可能会减慢,因为张量被放置在主机内存中,但是后续的tensor都会申请到显存上。考虑到一个典型的DL训练往往需要数百万个小批次,这种性能开销是可以忽略不计的。
运行时显存细粒度调整
- 此外,AntMan在运行时提供细粒度的GPU内存调度。如图7b所示,一个训练作业可能会收缩以确保其他作业的内存资源,并在其他作业完成后再增长。它说明了一个DL作业在T0时缩减,在T1时增加,代价是在主机内存上分配了一些张量。因此,在同一共享GPU中运行的作业在T0和T1之间对剩余GPU内存的使用是有保障的。
Computation Management
- 动态计算单元管理,用于控制DL训练作业的GPU利用率。
类似cgroup,可以在运行时动态地隔离DL特定进程的GPU计算资源访问。
当多个DL作业在同一个GPU上启动时,干扰主要是由潜在的GPU内核排队延迟和PCIe总线争用引起的,这会导致所有作业的性能一致下降,如果packing job是在相同的模型和配置上运行的话。
**如果不同的作业被打包在一起,作业会以不同的方式变慢。**这是因为作业在获取GPU计算单元方面有不同的能力。因此,作业性能在GPU共享中几乎无法保证或预测,导致多租户集群的GPU共享部署困难。
AntMan中,GPU运算器的执行是由一个新引入的模块负责的,称为GpuOpManager。
- 当GPU运算器准备执行时,它被添加到GpuOpManager,而不是直接启动。
- GpuOpManager的主要思想是通过延迟执行GPU运算符来控制启动频率。GpuOpManager通过这种方式来限制DL训练作业的GPU利用率。GpuOpManager不断对GPU运算器的执行时间进行分析,并在启动GPU运算器之前简单地分配空闲的时间段。
- 请注意,GpuOpManager只是延迟了GPU内核的执行。因此,运算符(包括GPU运算符和CPU运算符)之间的潜在依赖关系被保留下来,这意味着如果可能的话,CPU运算符可以继续。
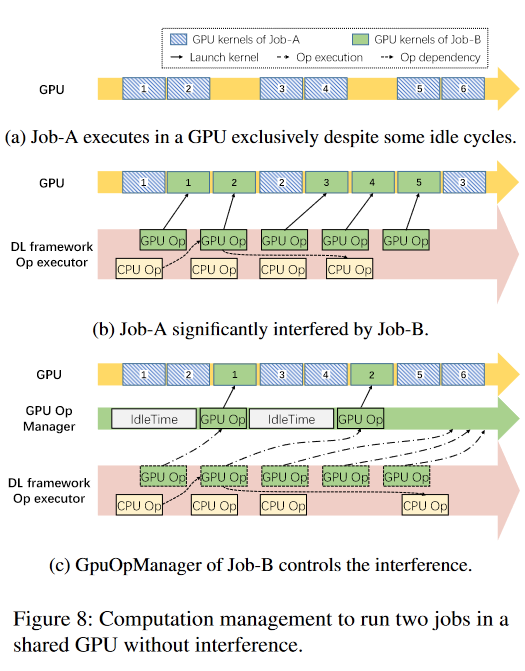
image-20220905151222951 图8说明了在同一GPU上执行的两个作业的GPU计算单元干扰的例子。图8a说明了Job-A是如何以细粒度的方式在GPU上执行的。简而言之,GPU内核将被按顺序放置,并由GPU计算单元逐一处理。请注意,在图8中,Job-A可能无法使GPU完全饱和,导致GPU周期闲置,GPU利用率低,有可能被其他作业使用。
因此,作业-B被安排在这个GPU上(图8b)。Job-B的GPU操作者启动在GPU中执行的内核(绿色块),这可以填满它,从而延迟其他GPU内核(蓝色块)的执行,导致Job-A的性能不佳。
这种干扰主要来自于缺乏控制GPU内核执行频率的能力。为了解决这个问题,我们在DL框架中引入了一个GPU运算器管理器(图8c)。
现有的DL框架一旦满足了GPU运算器的控制依赖性,就会在GPU运算器中发布GPU内核。在如图8c所示,第三个CPU操作符没有被阻止,然而,第四个操作符被延迟了,因为它依赖于第二个GPU操作符,它的执行被GpuOpManager延迟了。
Collaborative Scheduler
AntMan的整体架构
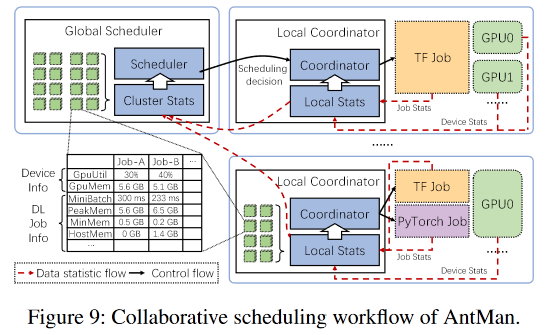
image-20220905152947633 - AntMan采用了一个分层结构
- 一个全局调度器负责job 调度
- 每个工作服务器都包含一个本地协调器,负责通过考虑DL框架报告的统计数据,使用动态资源扩展的基元管理作业的执行
- AntMan是为多租户GPU集群设计的。
- 在多租户集群中,每个租户通常拥有一定的资源,被注释为资源配额(即GPU的数量),这是可以分配给该租户的作业的并发性能保证资源。
- 每个租户的GPU资源配额之和小于等于一个GPU集群的总容量。
- 在AntMan中,工作被分为两种,由全局调度器应用不同的调度策略
- 资源保证型工作:资源保障型作业会消耗其相应租户的一定数量的GPU资源配额。AntMan确保资源保证作业的性能应该与独占执行的性能一致。
- 机会型工作:机会型作业则不会。
AntMan各模块的运作方式
- 调度决策可以被视为一个自上而下的控制流
- 在AntMan中,与传统的集群调度器类似,调度决策由全局调度器派发给本地协调器
- 本地协调器使用动态缩放机制对GPU资源进行内省式调度,以达到DL训练作业的目的
- 数据统计流信息由本地协调器的统计模块收集,并以自下而上的方式汇总到集群统计模块上
- 信息
- 硬件信息
- GPU利用率
- GPU内存使用率
- DL框架报告的详细作业信息
- 小型批次持续时间
- 峰值内存使用率
- 最小内存使用率
- 主机内存消耗等
- 硬件信息
- 这些信息可以帮助全局调度器做出作业调度决策
- 峰值内存和最小内存使用量是用来指示可以快速提供的GPU内存大小
- 批处理时间显示GPU内存多久可以用于另一个DL训练作业
- 信息
- 当作业在GPU服务器上启动,本地调度器管理其端到端执行
- 由于DL训练作业的负载波动,本地协调器以自省(introspective)的方式行事,对DL框架进行持续的作业控制
- 它从硬件和DL框架中收集所有作业的统计数据 -> 使用我们在第3.1节中介绍的新原语 –> 通过资源使用调整(例如,收缩GPU内存)–> 来控制作业性能
- 调度决策可以被视为一个自上而下的控制流
Scheduling Policy
目标
- 由于集群上的负载和作业的资源需求不断波动,在提供公平性(如确保DL作业的SLA,保证资源)和实现高资源利用率(如GPU利用率)之间存在着固有的矛盾。
- 普遍的生产型DL集群调度器经常以某些方式用公平性换取效率。
- 例如,空闲资源被分配给超额配置的租户。
- 然而,这样的GPU资源在没有抢占的情况下很难拿回来。一般来说,抢占很少被使用,因为它使正在运行的作业失败,同时浪费了昂贵的GPU周期。
- 此外,还报告了歧视大型作业的失序行为(即分配更多的GPU),导致倾向于小型作业的不公平。
- 首要目标:多租户公平性
- AntMan通过在全局调度器和本地协调器中实施的政策实现了公平性
- 这些政策由动态扩展机制提供支持。
- 第二优先:提高集群效率,从而实现更高的吞吐量
- AntMan中还引入了GPU机会主义工作,以窃取GPU中的空闲周期,从而最大限度地提高集群的利用率。
全局调度器:维护着工作到达的多个租户队列,决定为工作分配的GPU的位置
调度策略
- 对于资源保证型工作和机会型工作,AntMan应用不同的调度策略,如算法1所示。

image-20220905153001724 - findNodes是一个函数,它返回满足工作请求的节点和GPU候选者,并有一个可选的参数来指定约束。
- 全局调度器在有足够的GPU资源的情况下公平地分配资源保证作业。
- 除此之外,资源保证作业还可以使用空闲的GPU资源来最大化作业性能 。
- 如果一个作业的资源请求只能部分满足,全局调度器就会为这个作业保留资源。
- 保留的资源将永远不会被其他资源保证的作业占用,但是它们可以被机会主义作业所利用。
机会主义作业
- 默认情况下,全局调度器将估计没有设置GPU配额的作业的排队时间。排队时间长的作业将被自动作为机会主义作业执行。
- 目的:为了最大限度地利用自由资源。
- 它通过考虑实际的GPU利用率在GPU上分配机会主义作业。只有在过去10秒内利用率**低于M(目前设定为80%)**的GPU可以被选为候选。
- 在最空闲的候选人上分配机会主义作业(即minLoadNodes,第9-10行)。
- 分配在同一个GPU上的作业由本地协调者管理
AntMan默认会自动选择机会主义作业,但它也允许用户在提交时手动确定作业类型
- 明确指定为资源保证作业,以确保SLA
- 一个作业也可以被指定为机会主义作业,永远不会占用租户的资源配额
在实践中,用户通常以机会主义模式提交作业,以避免潜在的排队延迟,目的是进行调试和超参数调整,这都是由早期反馈驱动的。
本地调度器:协作执行共享GPU上的作业
如何在共享执行中确保资源保证作业的性能
- 一个GPU只会分配给一个资源保证作业,因为它消耗GPU配额
- 本地协调者首先限制机会主义工作使用GPU,防止资源保证工作受到干扰
- 在启动DL训练作业时,需要由DL框架初始化GPU设备
- 如果GPU处于高负荷状态,则需要更多时间。(初始化时占用更多资源)
- 一旦资源保证作业稳定执行,本地协调器将把剩余的GPU内存分配给机会主义作业。
- 通过监测作业性能(即小批量时间),在不干扰资源保证作业的情况下,逐步增加机会主义作业的GPU计算单元使用量
- 同样,当一个机会主义作业到达共享GPU时,本地协调器在不影响资源保证作业的情况下,以阶梯式的方式提高其GPU资源使用率。
如何处理资源保证作业的资源需求激增
- 为了意识到动态的资源需求,本地协调器监测DL框架报告的指标
- 当一个资源保证作业增加了GPU内存需求时,由于有了通用内存,张量被暂时使用主机内存存储。
- 本地协调者缩减其他机会主义作业的GPU内存使用量,并提高资源保证作业的GPU内存限制,以恢复其性能。
- 这对GPU计算单元的使用协调是类似的。
- 🚨AntMan依靠应用层面的指标(即迷你批处理时间)来表明资源保证作业的性能。如果它观察到资源保证作业的性能不稳定,它就会采取悲观的策略来限制其他机会主义作业对GPU资源的使用。
当一个GPU只被机会主义工作所共享时,最大限度地提高聚合工作的性能。
如果只有一个机会主义作业,那么GPU资源就可以被这个作业充分利用,而没有任何约束。
有时,一个GPU有可能被多个机会主义工作占用。
AntMan通过最大限度地提高GPU内存效率来优化聚合作业的性能。
在启用动态缩放机制后,我们发现不同的工作负载在内存限制带来的性能下降方面表现出不同的敏感性
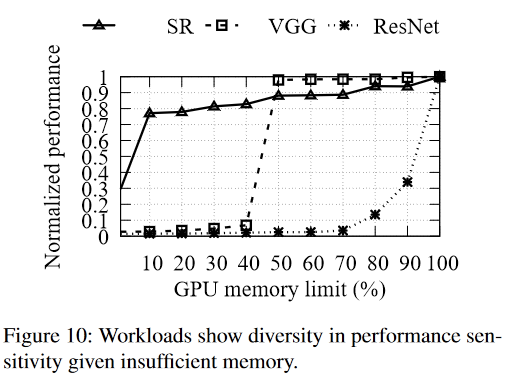
image-20220905153042457 如图10所示,
- SR模型即使在其设备内存减少90%的情况下,也只遭受了大约25%的性能下降
- Cifar10数据集上的VGG16[43]模型(VGG)即使在设备内存减少一半后,也能保持其大部分的原始性能。
- ImageNet数据集(ResNet)上的ResNet50[22]对内存缩减很敏感;10%的内存缩减会带来60%以上的速度下降。
当机会主义作业的总的GPU内存需求超过了GPU的内存容量时
- 将GPU内存分配给最能提高作业性能(Normalized Performance)的作业
Job 升级
- 机会主义工作虽然以best effort执行, 但这是在没有SLA保证的情况下。
- 全局调度器会在有足够资源的情况下升级这些作业,以快速完成它们。
- 全局调度器通知本地协调器,将其标记为资源保证作业,并消耗租户的GPU配额来完成作业升级。
- 对于分布式同步DL训练来说,部分升级没有帮助,因为一个工作者的性能下降可能会广播到整个作业。
- 因此,全局调度器检查所有GPU是否都被机会主义工作填满。
- 一旦所有的任务实例都准备好升级,并且资源配额足够,AntMan更愿意将机会主义工作升级,而不是新启一个工作。
Implementation
Deep Learning Framework
- 动态缩放机制在两个流行的深度学习框架中实现
- Pytorch
- Tensorflow
- DL框架的修改主要体现在三个部分:
- 内存分配器
- 为了实现动态的通用内存,(tensorflow ::BFCAllocator, PyTorch::CUDACachingAllocator)被修改以引入可调整的内存上限。内存分配器会跟踪内存分配的总字节数,并在总字节数超过上限时触发内存不足。
- 此外,还为内存分配器引入了一个新的接口,允许在任何时候清空缓存内存。
- 还增加了一个新的通用内存分配器UniversalAllocator,以包裹GPU内存分配器和主机内存分配器(即使用cudaHostMalloc进行内存分配)。
- 当张量的请求触发了内存分配时,UniversalAllocator试图使用GPU内存分配器来分配内存,
- 如果GPU内存剩余不足,则将CPU内存分配器作为备份。
- 🚨UniversalAllocator维护了一个集合数据结构,记录了由GPU分配的内存区域的指针,用来对内存指针进行分类,以便于回收。
- 执行器
- 为了实现动态计算单元的扩展,在DL框架中引入了一个带有运算器处理队列的GpuOpManager,它在一个独立的线程中运行。
- TensorFlow的运算器被相应地修改,以插入GPU Op到GpuOpManager队列中,从而将GPU运算器的执行专门交给它。
- GpuOpManager可能会根据计算能力的有限百分比来延迟GPU运算符的实际执行。
- 接口
- 内存分配器
- 内存使用模式的统计数据和执行信息被汇总到本地协调器上
- DL框架和本地协调器通过文件系统进行通信
- 他们都有一个监控线程来检查文件,以接收工作统计数据或控制信号
- 为了最大限度地减少内存管理的开销,内存的动态缩放是在mini-batch的边界(session.run()的结束)触发的
Cluster Scheduler
- 在Kubernetes上实现了一个自定义调度器,作为评估AntMan的原型。
- Kubernetes负责集群管理和执行Docker容器中的作业。
- 我们的全局调度器使用Python APIs来监控Kubernetes的API服务器中的事件,以便进行调度。
- 本地协调器作为DaemonSet部署在Kubernetes中。每个协调器监控文件系统的某些路径,以收集每个作业的报告信息。
- 汇总的作业和设备信息存储在ETCD中,这是Kubernetes中内置的分布式键值存储。因此,全局调度器在做调度决策时直接读取ETCD中的状态。
Evaluation
Benchmark
Trace Experiment
Cluster Experiment
Ralated Work
Conclusion
参考资料
- 论文地址:AntMan: Dynamic Scaling on GPU Clusters for Deep Learning | USENIX
- 代码地址:https://github.com/alibaba/GPU-scheduler-for-deep-learning
- 参考:OSDI'20 论文赏:ANTMAN: DYNAMIC SCALING ON GPU CLUSTERS FOR DEEP LEARNING | 高策 (gaocegege.com)