DeepUM: Tensor Migration and Prefetching in Unified Memory
摘要
- 深层神经网络(DNN)正在继续变得越来越广泛和深入。因此,它需要大量的 GPU 内存和计算能力。
- 本文提出了一个利用 CUDA 统一存储器(UM)实现 GPU 内存超订的 DeepUM 框架。
- UM 允许使用页面错误机制进行内存超订,但页面迁移会带来巨大的开销。
- DeepUM 使用一种新的相关性预取技术来隐藏页面迁移开销。
- 它是完全自动的,对用户是透明的。
- 我们还提出了两种最小化 GPU 故障处理时间的优化技术。
- 我们使用来自 MLPerf、 PyTorch 示例和 Hugging Face 的9个大规模 DNN 评估 DeepUM 的性能,并将其性能与6种最先进的 GPU 内存交换方法进行比较。
- 评估结果表明,DeepUM 对于 GPU 内存超订非常有效,可以处理其他方法无法处理的大型模型。
- UM 允许使用页面错误机制进行内存超订,但页面迁移会带来巨大的开销。
引言
背景
- 获得一个预先训练好的模型并用一个小系统对其进行微调是一种常见的做法
- 目前最先进的 DNN 模型是如此之大,以至于即使对模型进行微调也很难在小型系统上执行,特别是在单个 GPU 系统上
现存方案
为了解决这样的内存容量问题,人们进行了许多研究,例如
- 数据压缩[6,10,18,26,34]
- 混合精度算术[11,17,28]
- 数据重新计算[8,16,55]
- 内存交换[5,6,21,24,33,45,49-51,55]
其中,我们着重于 GPU 内存交换来解决 DNN 的存储容量问题。以前的内存交换方法分为两类。
- UM:使用 CUDA 统一内存[38]与页预取[5,35]
- non-UM:使用纯GPU 内存和内存对象换入换出[6,21,24,33,45,49-51,55]
统一内存(UM)提供 CPU 和 GPU 之间共享的单一地址空间。
它利用 GPU 页面错误机制在处理器之间按需迁移页面。
很少有 GPU 内存交换研究是基于 UM,因为由于地址转换和页面错误处理带来的巨大开销[4]
- 由于 UM 使用的虚拟内存需要为 GPU 中的每个内存请求进行地址转换
- 处理页面错误需要在 CPU 和 GPU 之间进行昂贵的 I/O 操作
尽管存在上述缺点,但在某些情况下,使用 UM 可能优于使用纯 GPU 内存。
- 首先,当内核需要的内存总量大于 GPU 内存容量时纯GPU 内存可能无法运行 CUDA 内核。
- 使用 UM,即使所需的页不在 GPU 内存中,CUDA 内核也可以执行,因为它们将通过页面错误机制按需迁移。
- 因此,UM 可以处理无法使用纯 GPU 内存处理的大规模 DNN。
- 其次,使用纯 GPU 内存可能会导致内存碎片。
- 在训练 DNN 时,GPU 内存分配/释放非常频繁。
- 即使流行的深度学习框架,如 TensorFlow [1]或 PyTorch [44]管理自己的 GPU 内存池,以最小化内存分配/释放时间和减少内存碎片,它们仍然存在一些内存碎片问题。
- 由于 UM 是一种虚拟内存,所以所有内存对象都以4KB 页面为单位进行管理。
- 因此,它遭受的内存碎片较少,更有可能运行大型 DNN 模型没有任何问题。
- 在训练 DNN 时,GPU 内存分配/释放非常频繁。
- 首先,当内核需要的内存总量大于 GPU 内存容量时纯GPU 内存可能无法运行 CUDA 内核。
在本文中,我们提出了一个名为 DeepUM 的框架,该框架利用 UM 允许超额订阅 GPU 内存,并实现了优化技术以最小化 UM 造成的开销。
- 设计
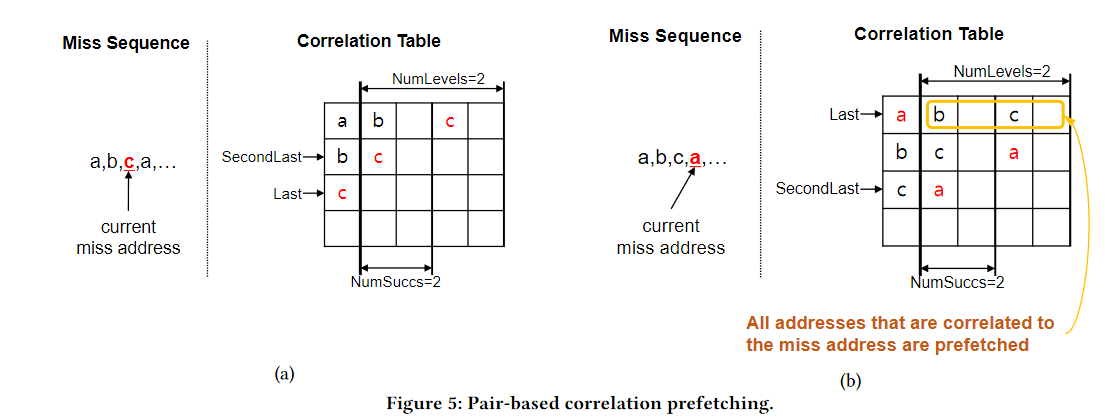
- DeepUM 修改了最初为缓存线预取开发的相关性预取技术,以预取 GPU 页面。
- 在各种预取技术中,我们选择相关预取[2,3,27,53] ,因为它与 UM 协同工作。
- 由于 UM 基于页面故障机制,故障访问由页面故障处理程序监视。
- DeepUM 可以使用从页面错误处理程序获得的错误地址轻松地记录错误页面之间的关系。
- DeepUM 利用了 DNN训练负载中内核执行模式及其内存访问模式大多是固定的和重复的这一事实。
- DeepUM 的相关表记录了
- DNN 训练阶段内核执行的历史
- 页面访问
- 它根据相关表中的信息预取页面,预测下一步将执行哪个内核。
- DeepUM 的相关表记录了
- DeepUM 修改了最初为缓存线预取开发的相关性预取技术,以预取 GPU 页面。
- 优化:
- 为了最小化故障处理时间,DeepUM 提出了两种优化技术,用于 NVIDIA 设备驱动程序中的 GPU 故障处理例程。
- 一种是基于相关表中的信息进行页面预收回。当 GPU 内存超额预订时,页面驱逐会增加页面错误处理时间,因为页面驱逐逻辑位于页面错误处理例程的关键路径上[32]。
- 另一个优化是当预期 PyTorch 不再使用页面驱逐受害者时,GPU 内存中的页面失效。这种优化消除了 CPU 和 GPU 之间不必要的内存交换
- 为了最小化故障处理时间,DeepUM 提出了两种优化技术,用于 NVIDIA 设备驱动程序中的 GPU 故障处理例程。
- 透明性:
- DeepUM 只需要对原始 PyTorch 源代码中的代码进行很少的修改(不到10行代码) ,就可以改变 PyTorch 内存分配器的行为。
- 此外,它不需要修改用户代码。用户代码描述 DNN 模型以及它是如何训练的。
- 设计
本文件的主要贡献概述如下:
- 我们提出 DeepUM 利用 CUDA UM 允许 DNN 的 GPU 内存超订。它使用相关性预取自动预取数据。
- 它是完全自动的,对用户是透明的。
- 我们提出了一种相关预取技术,专门用于 DNN 中的预取页面。
- 这两个相关表记录了 DNN 训练阶段的内核执行历史和页面访问模式。
- 我们提出了两种优化技术,以最大限度地减少 GPU 故障处理时间。
- 一个是新的页面预驱逐策略,加上相关性预取
- 另一个是当选择 PyTorch 作为受害页面时,使 GPU 内存中无用的 PyTorch 页面失效。
- 评估
- 模型
- 来自 MLPerf 的9个大规模 DNN模型
- PyTorch 例子
- Hugging Face [56]。
- 实验
- 我们将 DeepUM 与以前的六种 GPU 内存交换方法进行了比较。
- 结果
- DeepUM 实现了与之前需要手动优化的 GPU 内存交换方法相当的性能。
- DeepUM 比其余五种交换方法获得了更好的性能。
- 此外,DeepUM 可以运行批量大得多的模型,以前的方法无法运行这些模型。
- 模型
- 我们提出 DeepUM 利用 CUDA UM 允许 DNN 的 GPU 内存超订。它使用相关性预取自动预取数据。
背景
GPU 和 CUDA 编程模型
CUDA 统一内存管理
NVIDIA 页错误处理
DeepUM的总体设计
DeepUM的结构

DeepUMRuntime
DeepUMDriver
GPU页面的相关性预取