
EasyScale 论文阅读笔记
Abstract
- 分布式同步GPU训练通常被用于深度学习。
- 使用固定GPU的资源约束
- 使得大规模的深度学习训练工作受到影响
- 降低了集群的利用率
- 纳入资源弹性
- 往往会引入模型精度的非确定性<—–缺乏隔离能力
- 使用固定GPU的资源约束
- 本文介绍EasyScale,
- 这是一个弹性框架
- 可以在异构GPU上扩展分布式训练
- 同时产生确定性的深度学习模型
- 实现了弹性的精度一致的模型训练。
- EasyScale严格遵循数据并行训练流程
- 仔细追踪与精度相关的因素
- 有效利用深度学习特性进行上下文切换
- 为了使异构GPU的计算能力达到饱和
- EasyScale根据我们的作业内和作业间调度策略动态地分配工人
- 最大限度地减少GPU的空闲时间
- 并相应地提高综合作业的吞吐量。
- 实验
- 部署在CompanyA的一个在线服务集群中
- EasyScale为弹性深度学习训练作业提供动力,使其适时地利用空闲的GPU
- 在不违反SLA的情况下将集群的整体利用率提高了62.1%
- 这是一个弹性框架
Introduction
弹性深度学习框架很少在行业中使用
- 根本障碍:在使用不同资源进行训练时模型准确性不一致
- 资源弹性对训练程序和模型收敛都引入了非确定性。
- 通过调整特定基准中的超参数(如学习率或批量大小)收敛到类似的精度不能说服用户,因为预期的计算流程已经隐性改变。
- 在改变数据集或模型结构时,对模型准确性的非确定性的担忧仍然没有得到解决,这使得深度学习从业者在拥抱资源弹性时犹豫不决
EasyScale:
- 第一个在同构和异构 GPU 的资源弹性上实现一致模型精度的训练框架
- 提高了整体集群效率<—-通过尽最大努力利用空闲 GPU 来进行弹性模型训练
- 将深度学习模型训练视为科学实验,将确定性和可重复性作为第一流的目标
- EasyScale探讨了将分布式模型训练过程与硬件资源解耦的可能性
- 无论分配的GPU数量和类型如何,都能产生位数一致的模型
- 这是通过一个名为EasyScaleThread的抽象来实现的
- 它封装了从数据加载、采样、计算到通信的所有阶段
- 并使它们与在固定的GPU中执行的完全一样
- EasyScale利用深度学习的特点
- 实现了快速的上下文切换
- 解决了训练工作者状态的潜在非确定性
- 并在资源重新配置时有效地执行追踪和检查点
- EasyScale引入了一个工作内策略—->以负载平衡的方式在异构GPU上安排训练工人
- 进一步优化了工作间的资源分配—->以最大限度地提高总的吞吐量。
- 第一个在同构和异构 GPU 的资源弹性上实现一致模型精度的训练框架
贡献如下
- 我们调查了现有的弹性深度学习框架和异构环境中的非确定性行为,并对散布在整个DLT软件堆栈中的位数差异进行了溯源。
- 我们介绍用于弹性分布式模型训练的EasyScale,它以确定性的方式实现了一致的准确性。EasyScale利用EasyScaleThread来保持与PyTorch DDP相同的弹性训练行为,并以可忽略不计的开销有效地进行上下文切换。
- 我们引入了新的作业内和作业间调度策略,以提高单个EasyScale作业的吞吐量和聚合集群的吞吐量,从而灵活有效地利用异构的GPU。
- 我们在生产集群中全面部署了EasyScale,将弹性训练作业与在线模型服务放在一起,在满足模型服务SLA的约束下,显著提高了集群利用率。
Motivation
弹性训练带来的不确定性
不一致的模型精度
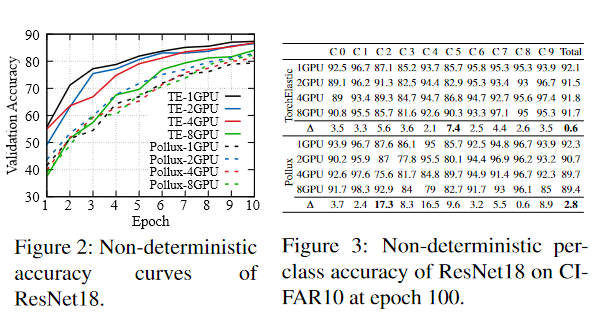
image-20221110093121968 用弹性框架进行模型训练的多次运行,未能在使用不同数量的资源时产生一致的模型精度。
- 图2说明了ResNet18在CIFAR10上的验证精度
- 实验条件
- 这是一个用不同数量的V100 GPU训练的弹性模型
- 超参数和随机种子与默认值相同,只使用不同分配的GPU
- TorchElastic(TE)被配置为调整学习率的线性缩放规则
- Pollux可以自动决定相应的学习率和批次大小
- 实验结论
- 与固定GPU上的分布式模型训练相比,资源弹性带来了不同的训练行为。
- Pollux在产生模型质量方面引入了相对较小的差异,然而,这种差异仍然是不可忽视的
- 实验条件
- 图3中报告了总体和每类的继续训练到100个epoch准确率
- 结果
- 总体准确率的差异仍然很明显:TorchElastic和Pollux分别为0.6%和2.8%。
- 每类准确率的差异甚至更大:达到7.4%和17.3%
- 结论
- 这表明弹性训练的模型与使用固定GPU的模型相比,偏差不同。
- 其他指标仍未披露,模型质量差距的上限仍然未知
- 结果
- 图2说明了ResNet18在CIFAR10上的验证精度
很难理解超参带来的影响
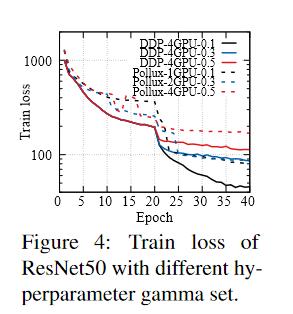
image-20221110093137841 研究人员很难推理出gamma如何影响训练损失曲线
- 图4显示了ResNet50在CIFAR10上的实验
- 实验设置
- 比较对象
- 固定4个GPU上的DDP训练
- 1/2/4个GPU上的使用Pollux的弹性模型训练
- 除了学习率调度器的一个超参数gamma外,其他配置都是一致的
- gamma决定了本实验中20个epochs后的学习率降低比例
- DDP实验以相同的设置运行了三次4-GPU训练,但gamma值分别为0.1、0.3和0.5
- Pollux也运行同样的实验,1个GPU的gamma为0.1,2个GPU的gamma为0.3,而4个GPU的gamma为0.5
- 比较对象
- 实验结论
- 使用DDP,可以清楚地推断出超参数gamma是如何影响模型训练过程的。
- 训练损失在前20个 epochs的三次运行中保持一致
- 之后,较小的gamma导致较小的训练损失
- 使用Pollux,研究人员很难推理出gamma如何影响训练损失曲线。
- 使用DDP,可以清楚地推断出超参数gamma是如何影响模型训练过程的。
- 实验设置
- 图4显示了ResNet50在CIFAR10上的实验
总结
- DL 模型现在是算法,框架和计算资源组合的结果,这是限制 DLT 作业使用弹性资源的根本原因
- 现有的弹性 DL 框架缺乏将资源与模型超参数解耦的能力—->无法提供与弹性训练一致的模型精度
- 我们需要支持弹性训练,同时保持一致的模型精度
Design
Overview
弹性训练应该生成与使用固定数量的GPU进行的DDP训练相同的模型参数
实现弹性准确度一致的模型训练的关键挑战是找到一种实用的方法,将一个GPU有效地分享给多个worker
EasyScaleThread
EasyScaleThread: 捕捉深度学习的训练过程并将其与硬件资源解耦
- 每个GPU都由一个EasyScale PyTorch worker启动。
- 原始训练worker的执行被视为EST的执行,它可以动态地分配给PyTorch worker进程。
- 在一个worker中,多个EasyScaleThreads轮流占用GPU进行计算。
- 使用
- 通过使用白盒方法,EasyScale通过用户注释将模型训练的关键步骤挂钩,数据加载、反向传播和模型更新,因此在mini-batch边界进行精度一致的上下文切换。
- 用户定义的模型训练语义,包括模型结构、数据增量、批次大小、优化等,都照常保留。
- 至于编程,用户考虑总的逻辑训练工作者的数量来决定超参数(如全局批处理量和学习率),这与他们使用固定GPU的经验相同,但自动受益于EasyScale提供的弹性。
执行
- mini-batch的执行:
- 输入数据被分割到所有的EasyScaleThreads中
- 一个GPU上每次执行一个EST时, 其他EST被冻结
- 在所有EasyScaleThreads完成后,mini-batch就完成了
- 当两个EasyScaleThreads切换时
- EasyScaleThread的训练状态需要被保存到GPU之外,因此要确保有足够的GPU内存给下一个EasyScaleThread,这可能是昂贵的。
- 在GPU上为每个minibatch有效切换EasyScaleThreads的关键是减少上下文切换所需的状态。
- 而EasyScale选择在完成前向后向计算后切换EasyScaleThreads,最大限度地减少GPUCPU内存拷贝。
- 我们通过以下方式最小化状态的大小:
- i)定位影响最终精度的非确定性来源,最小化需要记录的必要状态
- ii)利用DL的数据并行行为,最小化数据交换的工作集。
- EasyScaleThread的GPU内存中的工作集
- 可以分为时间张量和激活、模型参数和优化状态以及梯度,
- 处理
- 首先,对于时间张量和激活,它们在前向步骤中创建,在完成梯度生成后在后向步骤中销毁。
- 因此,它们会在小批处理结束时自动释放出来。
- 其次,关于模型参数和优化器状态,每个数据并行工作者在训练过程中都会保留一个副本,并且在一个小批处理结束时进行更新。
- 因此,在EasyScale中,当切换EasyScaleThreads时,它们可以被重复使用。
- 最后,梯度是根据EasyScaleThreads的不同数据输入计算的,因此不能重复使用。然而,梯度通常很小,并且只在minibatch结束时的分布式梯度同步中使用。
- 因此,在EasyScale中,我们在上下文切换时将梯度迁移到主机DRAM中,并与下一个EasyScaleThread的计算重叠。
- 首先,对于时间张量和激活,它们在前向步骤中创建,在完成梯度生成后在后向步骤中销毁。
- 通过这种方式,我们交替执行EasyScaleThreads,直到所有计算完成。之后,分布式同步被触发,模型更新被进行一次以完成小批量的计算。
- mini-batch的执行:
重配置
- 当资源重新配置被触发时,EasyScale采用按需检查点的方式来持续保持最小和必要的状态。
- 检查点包含了
- 所有EasyScaleThreads的上下文
- 额外的状态(包括训练进度和其他实现精度一致性的状态)
- 深度学习参数(例如,模型、优化器和学习率调度器)
- 与EasyScaleThread上下文不同的是
- 额外的状态和参数只需要一个副本,因为它们在mini-batch结束时对所有EasyScaleThread都是一样的。
- 请注意,在重新启动模型训练后,每个GPU的EasyScale运行时
- 会加载额外的状态和模型参数的副本
- 以及重新分布的EasyScaleThreads的相应上下文
优化
为了overlap数据加载和GPU训练
- data loader在独立的处理器中执行(即PyTorch中的加载器工作者进程),异步加载训练样本并执行数据增强(例如,裁剪或旋转图像)以建立训练批次。
- 在EasyScale中,我们优化了所有EasyScaleThreads之间共享data loader,因为每次只有一个EasyScaleThread在GPU上进行训练。
- 尽管共享了多个EasyScaleThreads,但数据消耗率与专用GPU中的数据消耗率相似。
为了实现data loader的共享
EasyScale采用了一个分布式数据采样器,该采样器共同考虑了EasyScaleThreads的全局index和时分模式,在一个队列中生成数据index
然后,这些数据索引被数据工作者有序地处理
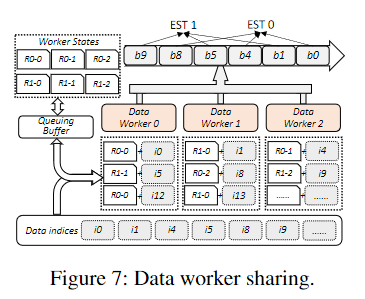
image-20221110211808582 - 图7显示了将三个数据工作者共享给两个EasyScaleThreads的情况,其中EasyScaleThread的总数量为四个(即图6中的2-GPU训练)。
- EST0和EST1的训练批次为:小批0的b0和b1,小批1的b4和b5。
- 在专用GPU中为EasyScaleThread i处理数据指数的数据工作者j的状态被表示为Ri-j
- 为了平衡负载,EasyScale中的数据工作者轮流从队列缓冲区中获取给定数据指数的相应状态(即Ri-j)进行预处理,完成后将状态提交回队列缓冲区中。
注意,由于data loader的异步执行–>
- data loader的进程通常在训练进度之前—>
- 为了跟踪和保持弹性的一致状态,引入了一个排队缓冲区来记录未被消耗的小批的必要状态—>
- worker的状态根据训练进度从队列缓冲区中去排队,然后在检查点中被视为额外状态的一部分
不确定性的溯源与解决
- 自上而下的方法来比较EasyScale和DDP, 我们发现非确定性的根本原因分散在训练管道的几乎整个软件栈中,从训练框架到通信,再到GPU内核。
- 首先,在训练框架层面
- 框架有一些状态需要在整个训练过程中保持一致,以保证确定性
- 尽管深度学习训练在DAG图中组织运算符(例如卷积、批量归一化),但一些运算符隐含地依赖一些状态,而不是其前辈的输出。例如
- Dropout依赖于GPU中的随机数发生器(RNG)状态;
- BatchNorm通过考虑工作者的等级来跟踪其运行状态;
- 数据加载器和数据增强的转化器依赖于Python、NumPy和PyTorch的随机状态,等等。
- 第二,在通信层面
- 通过全还原的梯度同步在资源弹性下是不确定的
- 在同步过程中,梯度被聚集到通信桶中,以优化通信性能。
- 梯度到桶的映射最初由DAG图的静态反转拓扑顺序决定。
- 它在第一个小批处理结束时根据收到的梯度张量的顺序进行重构。
- 然而,在弹性训练期间,工作者重新启动将重建通信渠道,这可能会影响第一个恢复的小批的梯度聚合顺序。
- 由于环形Allreduce的实现,这最终会引入非确定性。
- 最后,在GPU内核层面
- 为同一运算器选择不同的内核也会导致结果的细微差别
- 导致不同内核选择的原因有两个。
- 首先是框架、编译器或供应商库中的一些基于剖析的优化,在小批量中应用不同的内核实现,以收集性能统计数据,找到最佳匹配。
- 另一个是内核的实现可以与硬件相关。例如,一些内核实现是基于流处理器单元的数量、硬件特定的低位组件等,因此不能应用于所有类型的GPU。
- 首先,在训练框架层面
- 确定性的等级与应对方案
- EasyScale定义了不同级别的弹性训练的确定性,为用户提供明确的一致性保证,并设计了相应的处理方法来实现它们。
- D0:固定DoP的确定性
- –用固定的GPU资源进行多次训练应该产生相同的模型
- 实现D0需要训练框架及其所选内核的一致行为。
- 对于框架,我们在训练开始时固定RNG的随机种子,并在数据加载工作者状态中记录RNG的状态,在上下文中记录EasyScaleThreads的状态,以便EasyScaleThreads自动保持状态一致。
- 我们还禁用了最适合的算法选择,并选择了确定性的算法(例如,没有原子指令)。
- D1:弹性确定性
- –在检查点重启的情况下,用数量不断变化的同质GPU进行多次训练,应该产生相同的模型
- 在D0之外,D1需要解决通信层面的非确定性。
- 为此,我们为每个EasyScaleThread分配了一个固定的虚拟通信等级。
- 我们还将形成梯度桶的索引记录到检查点中。
- 重新启动后,在训练之前,首先用记录的指数重建桶。
- 后面的通信通道重建被禁止。
- D2:异质性确定性
- –用不同类型的GPU进行的多次训练应该产生相同的模型。
- 为了实现D2,我们开发了与硬件无关的GPU内核。具体来说,
- 1)我们修改内核实现(例如PyTorch中的reduce、dropout),限制SM和线程的数量;
- 2)我们通过向高层调用传递algo_id,强制选择相同的低层实现(例如cuDNN中的convolution,以及cuBLAS中的gemm、gemv)。
- 如何确定确定性等级
- 在EasyScale中,D0和D1是默认启用的,因为我们的实现对实现它们的开销可以忽略不计
- 实现D2对于某些类型的模型(如CV模型)可能会有较高的开销,因为它们不能对某些GPU类型使用一些供应商优化的内核(如卷积)。
- EasyScale可以透明地分析一个模型(通过扫描PyTorch nn.Modules),并识别它是否依赖于需要硬件特定内核优化的运算符。
- 如果不是,我们就启用D2,允许它使用异构的GPU,否则就限制它使用同构的GPU。
调度原则
- 用户在提交EasyScale作业时
- 可以指定一个maxP:即要启动的最大工作者数量,这也是作业执行过程中EasyScaleThreads的数量
- 用户还可以指定一个minP(>=0),表示所需的保证GPU
- 设置minP == maxP意味着作业将回到使用与DDP相同的固定DoP
- 小结:ESTi抽象 -> 确定性处理 -> 调度EST
- EasyScaleThreads(EST)的抽象将DL训练和底层GPU资源解耦,因此与DDP兼容的训练作业可以持续地在同质GPU的弹性数量上运行。
- 确定性处理实现了弹性训练下的精度一致性,即使是在异构GPU上
- 在异构GPU上调度EST的关键挑战在于计算能力的异质性和GPU内存的异质性。
- Pollux和VirtualFlow
- 采用为每一种GPU单独扩展批次大小的方法
- 对于EasyScale来说是完全不可接受的,因为它改变了固有的训练超参数,从而破坏了精度的一致性
- EST消耗固定计算能力与固定内存消耗
- 在EST执行过程中,每个EST消耗固定的计算能力,其中GPU的微架构特征(即SM数量和缓存大小)决定了理论能力。具有较高计算能力的GPU可以在一定时间内执行更多的EST
- 而每个EST都有固定大小的GPU内存使用峰值。此外,由于同一GPU执行器中的EST的内存是完全重复使用/共享的,执行器的内存用量可以代表EST的内存用量
- 为简洁起见,我们将固定的计算能力和内存用量分别定义为计算单元(CU)和内存单元(MU)
- 复杂的分析规划:避免因为严重的负载不平衡而造成重大的性能浪费
- Pollux和VirtualFlow
异构感知的EST规划
Planning CUs
- 分配策略
- 当分配的GPU是同质的,并且数量是maxP的一个因素时,在这些GPU上均匀地分配CU,因为所有CU都有相同的计算时间
- 在异构GPU的情况下,需要根据GPU的计算能力来分配CU以达到平衡,并最多消除空闲周期
- 我们提出了一个新的指标,叫做浪费,
- 即由于CU的整数倍和GPU的实际连续能力不匹配而浪费的计算能力,或者说是负载不平衡。
- 浪费主要包括两个方面:
- ∂异构GPU之间的负载不平衡,是由于用CU的整数倍不准确地逼近连续的实际计算能力造成的;
- ∑同构GPU之间的负载不平衡,是由于没有足够的CU分配来充分利用所有的GPU,因为CU的总量被maxP所限制。
- 因此,我们建立一个分析模型来量化浪费。
- 符号表示
- 可用的GPU数量表示为Ni,其中下标i代表GPU类型。
- 与工作负载相关的计算能力Ci被估计为每秒的小批处理数量。
- 分配给GPU类型i的CU的最大数目被表示为Ai。
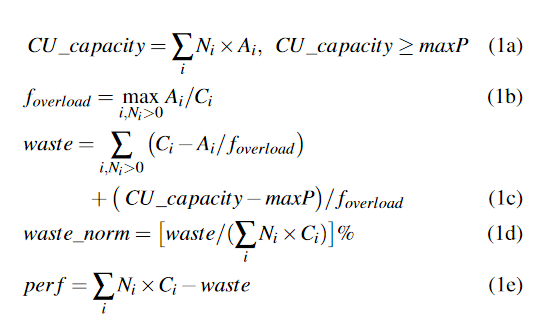
image-20221112203217230 - 为了确保所有EasyScaleThreads被执行,异构GPU上的最大CU总数(CU_capacity)应该大于或等于maxP(公式1a)。
- 过载系数foverload代表所请求的异构GPU的最大过载,其中过载被定义为每个计算能力的CU(等式1b)。
- 如果一个GPU类型承担了太多的CU,它就会成为性能瓶颈,并由于Sync-SGD而拖慢其他GPU的速度。因此,浪费被表述为:∂Ci和Ai之间的差距按foverload缩放,∑超额配置的CU_capacity按foverload缩放(公式1c)。
- 为了进一步区分当前Ni、Ci和Ai下的CU分配效率,得出了归一化的浪费百分比(公式1d)。
- 还得出了估计性能(等式1e)。
- 符号表示
- 分配策略
Planning MUs
异构GPU之间的内存容量也存在异质性
- 将MU分配给每个GPU的单个执行器可以最大限度地减少整体内存占用,因为EasyScaleThreads引入的内存开销可以忽略不计。
- 而且它们的MU可以完全重复使用。
- 因此,所有的GPU都显示出与MU相同的峰值内存使用量,导致具有较大内存容量的GPU出现闲置内存。
我们提出了一个多执行器的设计
它允许在GPU上分配一个以上的执行器,这样就可以同时执行多个EST。
具有较大内存的GPU可以权衡执行器数量和每个执行器的EST数量
- 同时保持 (#执行器 × #EST) 不变
- 例如,在分配了两个EST的情况下,有两种选择:
- a)<1执行器×2EST>
- b)<2执行器×1EST>
它拓宽了高效场景,即运行更多的执行器不会超过GPU资源(SM核、内存),即使考虑到干扰,仍然有助于提高性能。
推荐模型(如Wide&Deep)的训练通常显示出对GPU计算能力的利用不足,通常低于50%。在这种情况下,分配多个执行器可以利用剩余的计算能力,而且执行器之间不会产生不利影响,从而提高综合吞吐量。
我们还对(等式1)进行了调整,以对多个执行器的浪费进行建模。
- 与工作负载相关的计算能力Ci被MCi = m × Ci × Ii所取代,表示m个执行器的整体能力,其中包括干扰Ii。
- 分配给GPU Ai的CU数量由MAi = m × Ai取代,代表m个执行器的总CU数量。
EeayScale 调度器
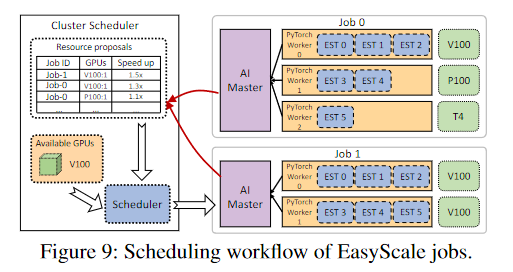
- 如图9所示,EasyScale采用了一个分层调度架构。
- 每个作业都包含一个作业内的调度器,名为AIMaster,它负责:
- a)在同质和异质GPU之间分配EasyScaleThreads,尽量减少浪费,使资源利用率最大化;
- b)通过估计潜在的速度提升,提出所需的资源进行扩展。
- 此外,一个集群调度器以全局模式行事,协调作业之间的资源。
- 每个作业都包含一个作业内的调度器,名为AIMaster,它负责:
- Intra-Job scheduler
- 基本职责:在给定的GPU下生成EST分配配置
- 首先,在当前可用的GPU下,它选择估计吞吐量最高的配置,并相应分配EST。
- 其次,它试图用一个增量的GPU来扩展,从而产生新的配置,并选择top-K的配置作为提交给集群调度器的建议。
- 配置组成与约束
- 由<nums, executors, threads, waste, perf>组成
- nums, executors, threads是具有相同长度的GPU类型的数组,分别代表GPU数量、执行器数量和每个执行器的EST数量
- waste和perf代表该配置通过分析模型估计的浪费和性能
- 这些配置应该满足集群总资源、minP、maxP和归一化浪费的阈值(实际为30%)的约束。
- 由<nums, executors, threads, waste, perf>组成
- 寻找可用配置
- 不同的工作负载使用不同GPU的吞吐量有差异,但在没有实际执行的情况下很难预测
- 因此,AIMaster模块使用作业的运行时执行统计数据来了解工作负载差异,并确定每个GPU类型i的工作负载相关计算能力Ci。
- 鉴于每个GPU类型i的剖析计算能力Ci,我们计算它们的整数近似值(例如,ceil(t×Ci), floor(t×Ci)),假设每个能力承担k个EST,并形成它们的组合
- 然后我们遍历这些组合,找到可用的配置。对于具有相同<数、执行器、线程>的配置,选择具有最小浪费的配置,其他配置则被过滤掉
- 配置回退
- 对浪费的估计有时可能是不正确的,这可能会导致更差的训练性能
- 一旦在重新配置后观察到性能下降,我们就会退回到使用以前的资源并释放新分配的资源
- 基本职责:在给定的GPU下生成EST分配配置
- Inter-job cluster scheduler
它通过考虑资源可用性和提案的优先级来响应AIMaster提案。
- 为了提高集群的整体利用率和聚合作业的吞吐量
- 它采用了一种启发式算法,倾向于接受每个GPU具有较高速度的建议,如算法1所示。
- 作业间调度器按照报告的平均加速比对建议进行降序排序。
- 然后,它对这些建议进行循环,开始接受最高的建议。
- 如果多个建议引入了相同的平均GPU加速,我们的调度器会优先考虑拥有更多GPU的建议。
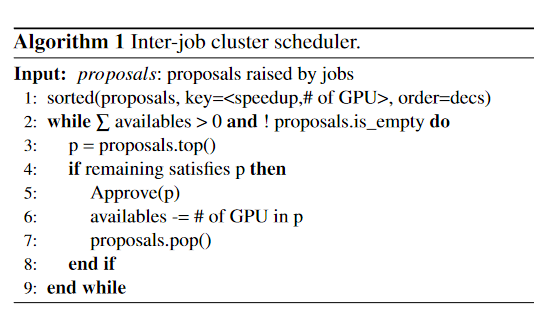
image-20221112210504940 集群调度器允许弹性作业最好地利用空闲资源
- 这些资源通常属于其他人,但暂时是闲置的。
- 然而,如果这些GPU需要返回,可能会触发抢占。
- 在这种情况下,集群调度器将尝试把与抢占的GPU相同的GPU分配给弹性作业。
- 当分配超时时,EasyScale作业会回落到利用它目前拥有的可用GPU。
Implementation
DLT 作业在具有 EasyScale 实现的 Docker 容器中运行。
- 在 Kubernetes 上实现了一个原型自定义集群调度器以进行评估。
- EasyScale 在我们内部的 GPU 集群调度器中得到了充分的实现,它是 Kubernetes 调度器的一个优化版本,可以为日常的 GPU 生产任务提供服务。
DL 框架中 EasyScale 的实现与 PyTorch 1.8 LTS 兼容。
- 它需要大约1,200行 Python 代码和2,000行 PyTorch 中的 C + + 修改代码,以及一个基于 PyTorch 实现的插件库。
- PyTorch 框架的 C + + 实现包括一个支持弹性的分布式数据并行通信库 ElasticDDP,它可以支持多个 EasyScaleThread 之间的通信,以全面减少梯度,并在触发资源弹性时在重新启动任务时始终如一地构建通信桶。
- 执行流控制和上下文切换作为 PyTorch 的附加组件在 Python 模块中实现。
实现了 AIMaster
- 为了决定负载平衡分配并控制作业以使用更多的 GPU 进行扩展
- 三个组成部分。
- 首先,我们通过一个 rpc 库收集 EasyScale 运行时报告的性能分析。
- 其次,我们提出资源建议并监视状态,从而通过 Kubernetes Python 告密者了解资源分配超时。
- 第三,实现策略控制器来计算增量资源请求并将其提交给集群调度器。为了支持资源弹性时的持续工作培训,我们采用按需检查点记录用户定义的模型,时代和小批量状态以及基本上下文切换状态
一个半自动剖析工具来执行张量之间的按位比较
- 从而找到运算符不一致的结果,识别资源弹性中不确定性的来源。