
《GaiaGPU:Sharing GPUs in Container Clouds》论文笔记
Abstract
- 对于云服务的提供商, 如何在容器间共享GPU, 是一个有吸引力的问题
- 容器的轻量与伸缩性
- GPU强大的并行计算能力
- 在云环境,容器需要使用一个或多个GPU来满足资源需要的同时, 容器独占式的GPU往往使用率很低
- 我们提出GaiaGPU,能够在容器间共享显存和算力
- 将物理GPU划分为多个虚拟GPU
- 采用弹性资源分配和动态资源分配来提高资源利用率
- 实验结果显示, 有效的实现了容器间资源的分配和隔离的同时,平均只增加了1.015%的开销。
Introduction
- 容器化是一种虚拟化技术
- 涉及到量身定制一个标准操作系统,方便它在一个物理机上运行由多个用户处理的不同应用程序
- 与VM模拟底层硬件不同
- 容器模拟的是操作系统
- 轻量,可伸缩,易部署
- 微服务打包与发布应用的事实标准
- 云服务提供商整合容器编排框架(如k8s)到基础架构中来提供容器云
- GPU 图像处理单元
- 有很强的并行处理能力
- 因为一个芯片上集成了数以千计的计算核
- GPU被广泛用于计算密集型任务,以加快计算
- 随着技术的发展趋势,现代GPU内将集成入越来越多的计算资源
- CUDA是多功能GPU最流行的平台,提供了API方便GPU的使用
- 卓越的性能吸引了很多云提供商将GPU引入云环境
- 在云环境中,部署在容器中的一个应用程序可能需要一个或多个GPU才能执行,
- 而另一方面,应用程序的专用GPU资源导致资源不足。
- 因此,如何在不同的容器中共享GPU对大多数云提供商都非常感兴趣
- 有很强的并行处理能力
- GPU虚拟化技术是在隔离的虚拟环境(例如VM, 容器)之间共享GPU的技术
- 多数的GPU虚拟化技术应用于VM, 容器间的虚拟化技术还在起始阶段
- 现阶段的基于容器的GPU虚拟化技术有以下局限性
- 需要特定的硬件设备(NVIDIA GRID)
- 将一整个GPU分配给单个容器, 不能共享 (NVIDIA Docker)
- 容器间只能共享GPU显存 (ConvGPU)
- 只支持单个GPU (ConvGPU)
- 我们提出GaiaGPU,能够在容器间透明地共享显存和算力
- 用户不用修改容器镜像来共享底层GPU
- 我们使用k8s的device plugin 框架将物理GPU划分为多个虚拟GPU
- 每个镜像可以按需分配一个或者多个vGPU
- 提供了两者方式在运行时更改镜像资源
- 弹性资源分配:暂时改变资源
- 动态资源分配:永久改变资源
- 用户不用修改容器镜像来共享底层GPU
- vGPU包括GPU显存和计算资源
- 共享显存
- 容器包含GPU显存的一小部分
- vGPU分配的是GPU的物理内存
- 共享计算资源
- 共享计算资源意味着每个容器都拥有GPU线程的一部分以并行执行计算。
- VGPU的计算资源由GPU的利用率衡量(采样时段内, 容器使用GPU的时间比例)
- 共享显存
- 总结:本文做了如下贡献
- 提出了GaiaGPU:一种在容器间透明共享显存与算力的方法
- 采用弹性分配和动态分配的方式提高了资源的利用率
- 进行了四个实验来验证GaiaGPU的性能。结果:实现了容器间资源的分配和隔离的同时,平均只增加了1.015%的开销。
Related Work
GPU虚拟化
被应用于在多个虚拟环境之间分享GPU, 极大地提高了应用性能
现存的多数GPU虚拟化技术基于VM,主要有三种虚拟化GPU
- API remoting
- vCUDA 和 rCUDA
- 创建GPU的封装库->劫持GPU调用->将重定向到host
- para and full virtualization
- GPUvm
- GPUvm将GPU显存和MMIO(存储器映射输入输出)分成几片,将片分给VM
- 硬件支持的虚拟化
- NVIDIA GRID
- 硬件虚拟化,创建虚拟GPU,挂在容器
- API remoting
与VM相比, 容器使用主机的操作系统->容器可以直接使用宿主机的GPU驱动->性能接近原生环境
- NVIDIA GRID
- 需要特定的硬件和与虚拟GPU要有相同的资源配置
- 一个容器只能分配一个虚拟GPU
- NVIDIA Docker
- 使得Docker镜像可以使用GPU
- 允许GPU驱动对CUDA镜像不感知
- 提供了一个命令行的封装->当容器启动时可以挂载driver的用户态组件和GPU设备文件
- 不能共享:只能把一整个GPU分配给一个容器
- ConvGPU
- 容器间共享GPU显存
- 它拦截了CUDA库来管理每个镜像显存的分配和回收
- 仅支持分享显存
- 而且只能虚拟化单个物理GPU
- GaiaGPU
- 软件层虚拟化,没有硬件限制
- 每个虚拟GPU的资源可以是不一样的
- 一个容器可以分配多个虚拟GPU
- 可以同时共享显存和计算资源
- 可以虚拟化多个物理GPU
- NVIDIA GRID
Device Plugin
- 致力于征聘各种计算资源(GPUs, NICs, FPGAs)供集群使用
- 无需改变k8s的核心代码
- 工作流
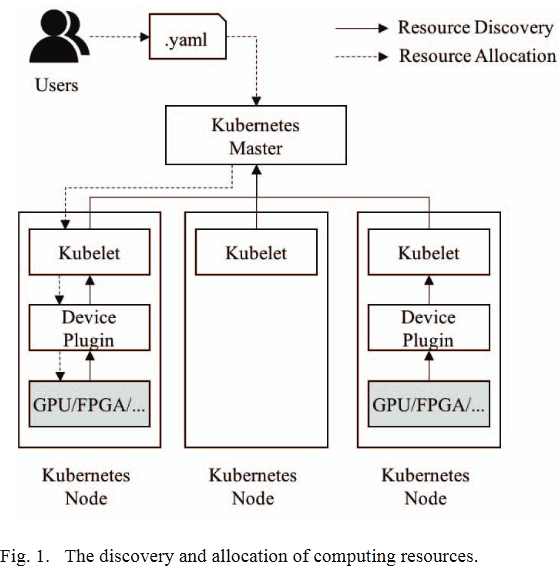
- 资源发现
- 实现Device Plugin
- 通过gRPC将device注册到Kubelet
- 成功注册后,device plugin发送设备列表
- Kubelet负责将这个扩展资源推广给Master
- 资源分配
- 用户在容器的specification中请求设备
- master的scheduler选择一个k8s节点的device plugin发送device请求
- device plugin分配对应的设备给容器
img
- 资源发现
- Vaucher通过利用设备插件框架来实现SGX(Software Guard Extensions)设备虚拟化,
- 该插件框架修改了Kubelet和SGX代码以限制虚拟SGX设备的设备内存的使用
- 仅处理内存资源
- 对内存施加严重限制
- GaiaGPU也采用了device plugin框架以在容器之间共享资源
- 对资源采用弹性限制而不是硬限制->来改善利用率
Design And Implementation
设计与实现
- 目标:在容器间共享显存与计算资源,使用最小的成本获得最大的提升
- 挑战:
- 透明性:
- GaiaGPU不应该修改k8s的代码或者容器镜像
- 使用共享GPU就如同使用物理GPU一样
- 低开销
- 使用共享GPU的性能尽可能接近使用物理GPU
- 隔离
- GaiaGPU应该管理GPU资源在每个容器的分配与回收
- 共享GPU时容器之间完全隔离
- 透明性:
- 结构:
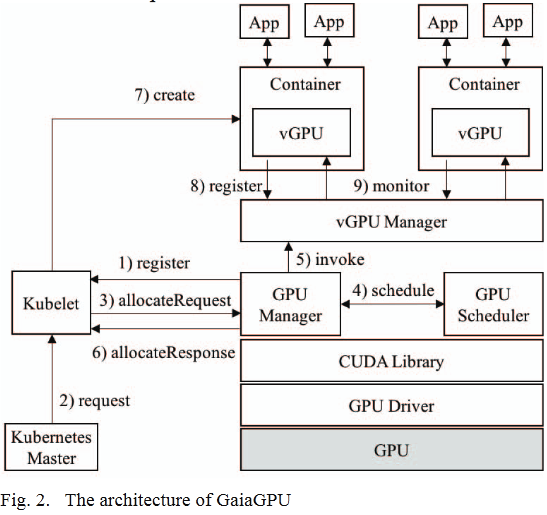
image-20220828143547571 - 两层资源管理
- host层:
- GPU Manager负责创建vGPUs
- GPU Scheduler 负责分配物理GPU资源到vGPUs
- 容器层
- vGPU Library负责管理具体容器的GPU资源
- host层:
- 组件
- GPU Manager
- device plugin:运行在host上负责创建vGPUs,使用gRPC与Kubelet通信
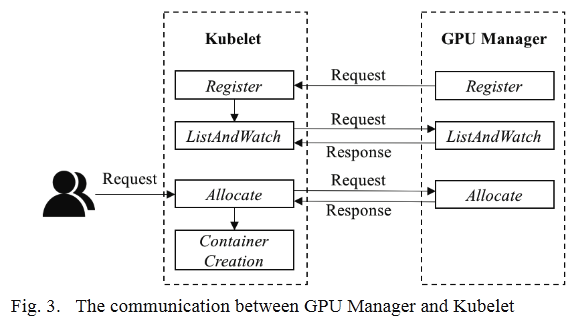
image-20220828171002587 - Register:GPU Manager将自身注册到Kubelet以通知其存在
- ListAndWatch:成功注册后,Kubelet调用ListAndWatch获取设备信息List
- 显存:256M 作为一个单元, 每个单元都被称作一个vmemory设备
- 计算资源:一个GPU被分作100份vprocessor设备, 每个vprocessor都有百分之一的利用率
- Allocate:
- 映射过程
- Kubelet发送随机选择的设备IDs到GPU Manager
- GPU Manager根据得到的设备IDs计算所需的物理GPU资源
- GPU Manage 发送一个请求到 GPU Scheduler
- GPU Scheduler 返回要分配给容器的物理GPU
- 映射完成后,GPU manager返回一个allocateResponse, 包含获取分配到的设备的Configurations
- 容器的环境变量
- 挂载到容器的目录和文件
- 分配的设备
- Kubelet将这些配置发送到容器运行时
- 映射过程
- GPU Scheduler
- 负责处理GPU Manager发来的调度请求
- 基于拓扑树分配GPU,树的根节点是host, 树的叶节点是物理GPU
- 当所需要的资源少于一个物理GPU,分配策略会最大程度减少资源碎片
- 当所需的资源等于一个物理GPU时,采用了最小化单叶节点(即没有兄弟姐妹节点的叶子节点)的分配策略。
- 当所需的资源不止一个物理GPU时,分配策略的目标是最大程度地降低GPU的通信成本。通信成本取决于两个GPU的连接模式。
- vGPU Manager
- 运行在host,传递容器配置并且监管分配了vGPUs的容器
- 当容器申请GPU资源时,GPU Manager将配置发送给vGPU Manager,例如
- 需要的GPU资源
- 该容器的name
- 接收到配置后,在主机上为容器命创建一个唯一的路径
- 路径名为容器名
- 这个路径包含在allocateResponse里
- 容器的配置也包含在这个路径里,所以可以通过Kubelet传递到容器
- vGPU Manager 和 vGPU Library是 服务器-客户端模式
- vGPU Manager 维护一个活着的且分配了GPU资源的容器的list
- 会定期检查这些容器是否存活
- 如果容器死了,从list中移除这个容器的信息,并且删除目录
- vGPU Library
- 运行在容器中,管理容器的GPU资源
- 在容器第一次执行GPU程序时被加载
- 启动后vGPU Libraray 向 vGPU Manager注册自身
- 利用LD_LIBRARY_PATH机制拦截CUDA库中内存与计算相关的API
- LD_LIBRARY_PATH是一个linux系统的环境变量
- 可以影响程序的runtime link
- 允许某些路径先于standard set of directories(?标准库目录?)加载
image-20220828222012346
- 当容器需要的GPU资源超出它申请的资源时,为了避免耗尽整个GPU,有两种资源限制策略
- 硬限制(hard limiit):如果容器资源消耗量超过配额,就不再给该容器分配资源
- 弹性限制(elastic limit):如果容器资源消耗量超过配额,但是系统中还有空闲资源,那么该容器仍然能够得到更多的资源
- 内存资源的限制采用硬限制策略, 因为
- 内存资源大小能决定一个程序能否运行,但对运行的效率影响较小
- GPU是计算设备,它们采用一次性资源分配策略。仅在获取所有内存资源后才可以执行应用程序,并且在完成内存之前不会释放。如果使用弹性内存分配,则具有较大内存需求的应用程序将饿死
- 撤回过度分配的内存资源的唯一方法是通过抛出out-of-memory exception来杀死该过程
- 计算资源采用弹性限制策略,因为
- 计算资源对程序运行的影响很大
- 计算资源(GPU 线程)在执行之后会立刻释放掉
- GPU Manager
- 总结:
- Step 1:GPU Manager向Kubelet注册自身,并报告vGPU的信息(ListAndWatch)
- Step 2:Kubelet接收到来自Master的创建一个GPU容器的请求
- Step 3:Kubelet发送一个allocateRequest到GPU Manager
- Step 4:GPU Manager发送一个vGPU调度请求到GPU Scheduler,GPU Scheduler根据调度策略选择实际提供资源的物理GPU。如果调度成功返回一个包含该物理GPU的信息的reponse
- Step 5:GPU Manager将容器配置信息发送到vGPU Manager
- Step 6:GPU Manager将容器环境变量,挂载信息和设备信息通过allocateResponse返回给Kubelet
- Step 7:Kubelet根据allocateResponse创建并且初始化一个容器
- Step 8:vGPU Library向vGPU Manager注册自身并且管理其所在容器的GPU资源
- Step 9:vGPU Manager持续监控GPU容器状态
image-20220828143547571
优化
- 容器的资源不仅会影响应用程序的性能,而且还会确定应用程序的状态
- 用户在创建容器时无法准确估算所需的资源
- 因此,我们提供两种方法来更改运行时容器的资源。弹性资源分配会暂时修改容器的计算资源限制,而动态资源分配永久改变了容器的资源。
弹性分配策略
- 目的是使用闲置的计算资源以提高资源利用率

image-20220828224059056 - nanosleep()是Linux内核函数,会挂起当前线程等待一段时间或者直到接收到调用当前线程的信号(Line 2)
- 为了防止过载, $GU_{max}$ 默认的最大值是90% (Line 3)
- 如果物理GPU计算卡仍然有空闲资源,也就是说GU free > 0,即使容器的资源请求已经超出其配额,vGPU Library也会继续给容器分配计算资源(Line 4-5)。如果系统没有剩余的空闲资源(*GU free <= 0*)并且容器的消耗的资源大于其配额,vGPU Library会逐渐收回超额(over-allocated)资源(Line 6-7)
- 超额资源的回收采用非抢占式策略(non-preemptive strategy),就是说会等到容器中占用线程的核函数执行完后再回收线程资源。CU cores*可以被理解为一种token,容器执行核函数时需要消耗该token,当核函数执行完成释放线程资源时容器又回重新拥有该token。CU cores的初始值等于容器的计算资源配额,CU cores为零时(系统没有空闲的资源,并且该容器的计算资源配额都正在被用于执行核函数),vGPU Library不会再给容器分配任何计算资源,直到容器的CU cores大于零(其他容器释放了空闲资源,或者该容器有核函数完成释放了资源,容器重新获得CU cores*)
- 弹性分配的样例
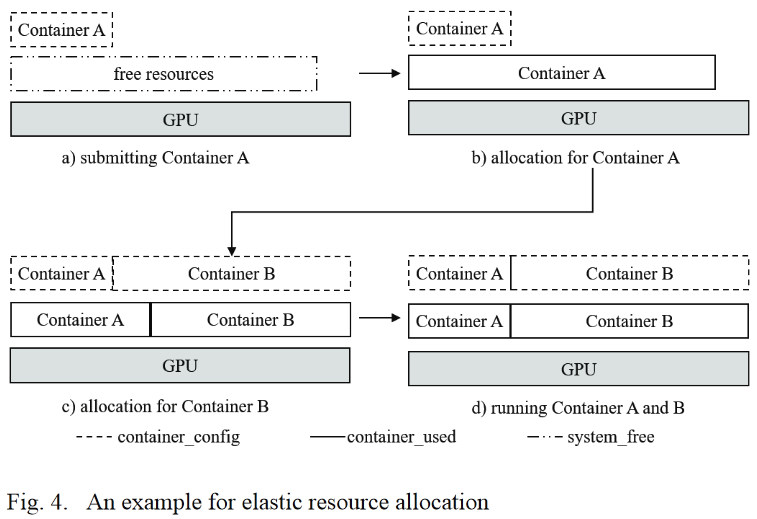
image-20220828233026263 - 首先,容器A申请了0.3个GPU,并且被GPU Scheduler调度到了一个完全空闲的GPU上
- 由于GPU完全空闲,所以容器A会逐渐占用所有的空闲资源,默认最大可占用90%
- 此时容器B申请了0.7个GPU,也被调度到了此GPU上,但是由于容器A占用了所有的空闲资源,所以需要从容器A回收超额线程资源并分配给容器B
- 重复经过几次资源的重新分配,容器A和容器B所占用的资源与其资源配额相同
动态分配策略
- 动态资源分配会修改容器资源,包括内存和计算资源,而无需停止容器。
- 动态资源分配旨在解决两个问题
- 在硬限制下更新容器的内存和计算资源
- 在弹性限制下将内存资源添加到容器中
- vGPU Library 通过将容器的资源配置与容器的实际使用进行比较来限制容器资源
- 要永久更改容器的资源:修改容器的资源配置—>通知GPU Scheduler->更新相应的物理GPU分配
Experiments
…
Conclusion
…