
Heterogeneity-Aware Cluster Scheduling Policies for Deep Learning Workloads
Abstract
- 背景
- 加速器,如 GPU、 TPU、 FPGA 和定制 ASIC 表现出跨模型架构的异构性能行为。
- 现有的针对加速器集群的调度器(用于在许多用户之间仲裁这些昂贵的培训资源)已经展示了如何针对各种多任务、多用户目标(如公平性和完成时间)进行优化。不幸的是,现有的调度程序基本上不考虑性能异构性。
- 异构感知调度器 Gavel
- 它系统地推广了大量现有的调度策略。Gavel 将这些策略表示为优化问题,然后使用我们称为有效吞吐量的抽象将这些问题系统地转换为能够识别异构性的版本。
- 然后,Gavel 使用一种基于循环的调度机制,以确保在给定目标调度策略的情况下,作业能够得到理想的分配。
- Gavel 的异质性感知策略允许异质集群维持更高的输入负载,并且与异质性不可知策略相比,最终目标如完成时间和平均工作完成时间分别提高了1.4倍和3.5倍。
Introduction
背景
- 我们的研究小组在其私有集群中拥有 NVIDIA Titan V、Titan X 和 P100 GPU。
- 这些多租户设置中的资源通常由调度程序仲裁。
- Themis [40]、Tiresias [28]、AlloX [37] 和 Gandiva [58] 等 GPU 集群调度程序因此需要决定
- 如何为多个用户分配
- 同时实施复杂的集群范围调度政策,优化目标,例如公平或完工。
不幸的是,由于以下三个原因,很难在这种情况下选择最有效的加速器类型:
- 性能异质性。由于各种架构差异,常用模型显示出跨加速器类型的异构性能行为。
- 一些调度策略也可以受益于在多个资源类型之间拆分作业:例如,最小化受延迟 SLO 影响的作业成本(例如,在 10 小时内完成作业)可能涉及使用更便宜的加速器开始训练,然后切换到满足 SLO 的更快、更昂贵的设备。
- 因此,即使是简单的单一作业设置,加速器类型的选择也很重要,并且取决于作业和策略。这在多工作设置中变得更加复杂,因为授予所有工作他们的可能无法同时使用首选加速器。
- 现有的调度程序,如 Gandiva、Tiresias 和 Themis 不考虑这种异构性能行为。
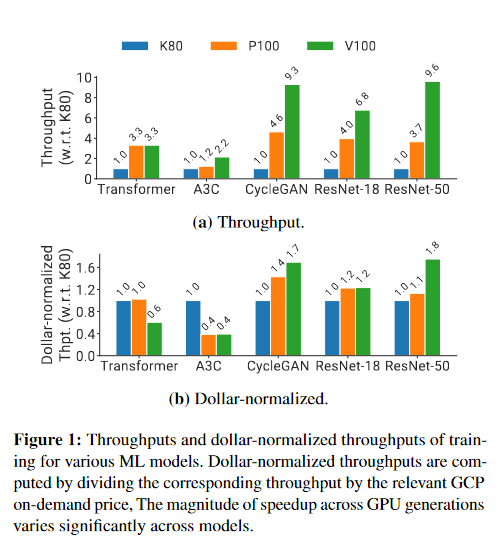
image-20230220122906946 - 图 1a 显示,与 K80 GPU 相比,ResNet-50 模型从 NVIDIA V100 GPU 获得近 10 倍的加速,而 A3C 深度强化学习模型仅获得 2 倍的加速。
- 然而,如图 1b 所示,当我们考虑每美元训练的样本数量时,V100 不再是所有模型的最佳选择——对于许多模型,较旧的 P100 GPU 在每美元基础上具有竞争力或更便宜。
- 调度策略之间普遍性。
- 集群操作员可能希望根据其业务目标实施不同的调度策略,例如优化
- 完成一组批处理作业的时间 (makespan)、
- 临时作业的公平性,
- 或更复杂的分层策略,
- 将资源分配给高层实体(例如,部门)使用一种策略,
- 然后实体内的个别工作使用另一种 [34]。
- 在数据分析集群中,许多作业调度程序已经支持分层分配策略 [Hadoop、Spark、YARN、Delay Scheduling]。
- 最近提出的两个考虑异构资源的 GPU 调度程序 AlloX [37] 和 Gandiva-fair [18],针对单个调度目标进行优化,并将其调度机制与该目标紧密耦合(例如,最大-最小公平性)。因此,它们无法轻松支持实践中经常使用的更复杂的策略。
- 集群操作员可能希望根据其业务目标实施不同的调度策略,例如优化
- 托管和安置优化。
- 为了提高集群利用率,现有的 GPU 调度程序经常部署优化,例如
- Gandiva [58] 中的空间共享,其中多个作业可以同时使用相同的加速器,
- 以及 Themis 和 Tiresias [28, 40] 中的布局敏感性,这涉及谨慎将任务放置在分布式作业中以确保良好的扩展性能。
- 在针对全局调度目标进行优化时,应明确考虑这些优化的性能优势,因为这些优化在以异构感知方式部署时更加有效。
- 我们表明,与 Gandiva 的ad-hoc方法相比,对空间共享进行显式建模可以将目标提高 2.2 倍。
- 为了提高集群利用率,现有的 GPU 调度程序经常部署优化,例如
- 性能异质性。由于各种架构差异,常用模型显示出跨加速器类型的异构性能行为。
在本文中,我们介绍了 Gavel,这是一种新的集群调度程序,专为本地和云部署中的 DNN 训练而设计,它有效地结合了硬件加速器和工作负载中的异构性,以推广广泛的现有调度策略。例如,Gavel 可以提供公平共享/最少实现服务 [28]、FIFO、最小完工时间、受 SLO 约束的最低成本、完成时间公平性 [40]、最短工作优先和分层策略 。
- Gavel 的主要观察是,许多广泛使用的调度策略(包括分层策略)可以表示为优化问题,其目标是作业实现的吞吐量的函数。
- 例如,最少达到的服务相当于最大化作业之间的最小缩放吞吐量,完工时间相当于最小化最大持续时间(计算为迭代次数与达到的吞吐量之比)等等。
- 鉴于调度策略的优化问题,Gavel 引入了一种通用方法来转换问题,使其具有异质性、协同定位和放置感知能力。
- 特别是,Gavel 将问题更改为
- 搜索每个作业的异构分配,花在各种资源配置上的时间比例(例如,60% 的时间在 V100 GPU 上单独运行,40% 的时间在 A100 GPU 上共享空间)与另一项工作),
- 并将目标函数中的吞吐量项更改为有效吞吐量,即作业在其分配的资源组合中的平均吞吐量。
- 需要添加额外的约束以确保返回的分配有效。
- 我们表明,即使对于具有数百个 GPU 和作业的集群,Gavel 的转换优化问题也能高效执行,并且可以支持广泛的策略。许多这些问题都可以使用一个或多个线性程序的序列来解决。
- Gavel 对每个作业的异构感知分配需要映射到实际的调度决策(在指定的持续时间内将作业放置在集群中的特定资源上)。
- 为实现这一点,Gavel 使用基于轮次的抢占式调度机制来确保作业接收的资源与计算的目标分配相似。
- Gavel 的调度机制需要能够调度同时请求多个加速器的分布式训练作业,以及由于空间共享而在给定加速器上同时运行的作业组合。
- Gavel 透明地做出这些调度决策:
- 它在调度程序和应用程序之间指定了一个 API,允许在现有深度学习框架(如 PyTorch [48] 和 TensorFlow [13] 中编写的作业以最少的代码更改在资源之间移动,
- 并使用类似的机制到 Quasar [21] 来估计并置工作的绩效测量,当先验不可用时,这些测量需要作为 Gavel 政策的输入。
- 通过明确考虑性能异质性,Gavel 提高了各种策略目标(例如,平均作业完成时间或 makespan):
- 在较小的物理集群上,它将平均 JCT 提高了 1.5 倍,
- 在较大的模拟集群上,它增加了一个集群可以支持的最大输入负载 ,同时将平均作业完成时间提高 3.5 倍,完工时间提高 2.5 倍,成本降低 1.4 倍等目标。
- Gavel 的主要观察是,许多广泛使用的调度策略(包括分层策略)可以表示为优化问题,其目标是作业实现的吞吐量的函数。
总而言之,我们的主要贡献是:
- 一种将现有集群调度策略转换为考虑异构和托管的等效策略的系统方法;
- 这些等效的优化问题对于当前的 DNN 集群是实用的
- 基于轮次的调度机制,以确保集群实现这些策略返回的分配。
- 对我们框架中的许多现有政策进行概括,以改进相应的目标。
Background
DNN训练
System Overview
- 给定一组作业,Gavel 在常驻作业中仲裁集群资源(以不同类型的加速器的形式),同时针对所需的集群目标进行优化。
- 这是通过两步过程完成的:
- 首先,异构感知策略计算不同作业(和组合)应在不同加速器类型上运行的时间分数,以优化预期目标。这些策略需要输入每种加速器类型上每个作业的性能行为(根据吞吐量)
- 这些行为可以由用户提供
- 也可以由 Gavel 的吞吐量估算器即时测量
- 分配在仅在分配重新计算事件之间是重要的
- Gavel 可以在重置事件发生时(作业到达或完成,集群中的 worker 失败)或以周期性时间间隔重新计算其策略
- 给定策略的输出分配,Gavel 的调度机制授予作业在不同资源上的时间,并根据需要在工人之间移动作业,以确保每个作业在不同资源上花费的时间的真实比例与策略返回的最优分配非常相似。 Gavel 的工作流程如图 2 所示
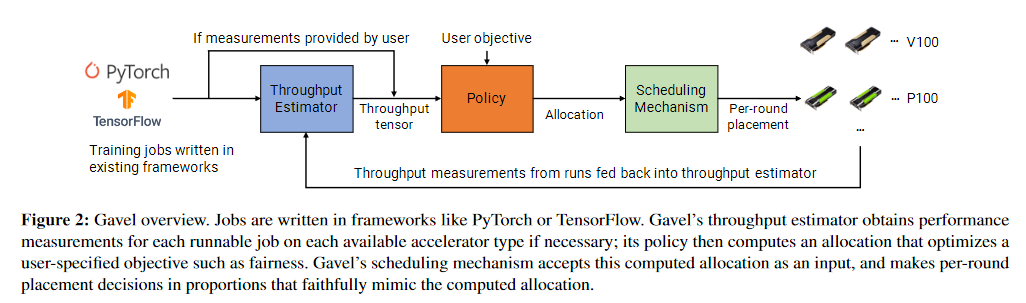
image-20230220133715374
- 首先,异构感知策略计算不同作业(和组合)应在不同加速器类型上运行的时间分数,以优化预期目标。这些策略需要输入每种加速器类型上每个作业的性能行为(根据吞吐量)
- 这是通过两步过程完成的:
异构感知的调度策略
Gavel 将调度策略表示为各种感兴趣目标的优化问题,例如公平性或完工时间,并将分配表示为矩阵,指定作业在分配重新计算之间应花费在每种加速器类型上的挂钟时间的分数。矩阵 X 可以表示单个加速器类型(同类设置)、多种加速器类型(异构设置)以及其他优化的分配。考虑 X 示例:
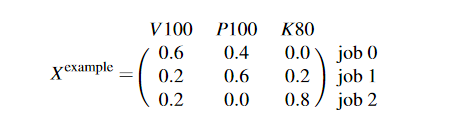
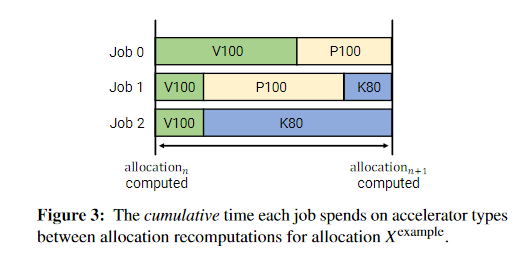
根据在三个作业和三个加速器类型上指定的分配,作业 0 应该花费 60% 的时间分配在 V100 GPU 上有效,其余 40% 的时间在 P100 GPU 上。这在图 3 中直观地显示了。
Gavel 在给定表示为优化问题的策略的情况下为矩阵 X 找到最优值。为了构建给定策略的优化问题,Gavel 需要一个吞吐量矩阵 T,其中包含每个作业在不同加速器上的吞吐量(每秒训练迭代次数)。如果作业 m 不在加速器类型 j 上运行(例如,由于内存限制),则可以将 Tm j 设置为 −∞。
给定 T 和 X,我们将模型 m 的有效吞吐量定义为跨加速器和作业的时间加权平均吞吐量。为简洁起见,我们将此数量表示为 throughputT (m, X) 或简称为 throughput(m, X)(去掉 T)。对于没有空间共享的分配 X,
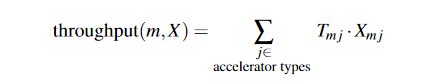
不同的集群调度策略可以表示为 X 最大化或最小化适当目标函数的优化问题。需要指定约束以确保 X 是有效分配。最大化总有效吞吐量的假设策略看起来像,
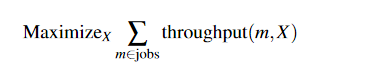
受以下限制:
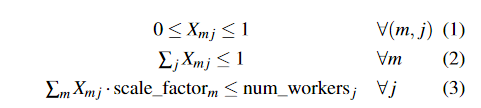
这些约束确保每个工作-工人分配都是非负的且介于 0 和 1 之间(等式 1),工作的总分配不超过 1(等式 2),并且分配不会超额分配工人(等式 3) ).
空间共享。 Gavel 的分配矩阵也可以包含空间共享 (SS)。虽然之前的工作使用贪婪算法进行空间共享,但我们发现,根据它们消耗的资源,不同对的 DNN 应用程序在实践中在并置在一起时具有截然不同的性能(图 4)。使用空间共享时,X 需要包含每个可行的作业组合的行,并且 T 需要具有作业组合的吞吐量,例如:
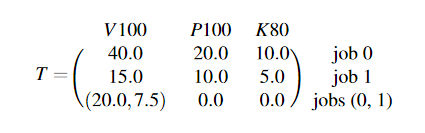
SS 感知分配 X 规定了每个作业组合应该花费在每种加速器类型上的时间分数。
我们将 T 的条目限制为最多 2 个工作的组合;我们根据经验发现,较大的组合很少会增加净吞吐量。此外,尽管 T 的大小随着工作数量的增加呈二次方增长,即使工作组合的大小为 2,我们发现在实践中我们只需要考虑实际表现良好的组合。我们在 §7.4 中评估了这些 SS 感知策略的缩放行为。
我们将 T 的条目限制为最多 2 个工作的组合;我们根据经验发现,较大的组合很少会增加净吞吐量。此外,尽管 T 的大小随着工作数量的增加呈二次方增长,即使工作组合的大小为 2,我们发现在实践中我们只需要考虑实际表现良好的组合。我们在 §7.4 中评估了这些 SS 感知策略的缩放行为。
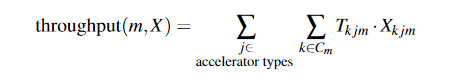
约束也需要稍微修改,以确保 X 是这个新制度中的有效分配:
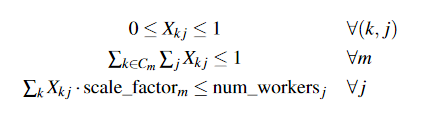
Cm 是包含作业 m 的所有作业组合的集合。
位置敏感性。同样,Gavel 的分配矩阵也可以扩展以包含位置敏感性。观察到的分布式作业的吞吐量取决于任务的位置以及模型和加速器类型(速度较慢的工作人员不太可能受到通信限制,

这意味着任务合并的效率较低)。我们可以通过考虑分布式作业在以下方面的性能来使我们的策略对位置敏感:1) 统一设置,其中尽可能多的加速器在同一台服务器上(例如,如果使用 8-GPU 服务器,则每台服务器 8 个 GPU), 2) 一个未合并的设置,其中加速器位于独立的服务器上。这些是布局空间中的极值点,是性能的上限和下限。我们可以在我们的策略中对此进行建模,方法是让两种不同的工作人员类型(合并的和未合并的)在 T 中具有相应的吞吐量值,在 X 中分配值。
基于轮次的调度机制
在计算出最优分配后,Gavel 的下一步是将作业(或作业组合,在 SS 的情况下)分配给加速器类型,同时尽可能匹配最优分配。也就是说,要实现上面的分配$X^{example}$,调度机制需要保证在集群中只有作业0、1、2这三个可运行的作业的时间段内,作业应该按照自己计算出的最优时间获得资源分数。
为此,调度程序会为每个作业和加速器类型组合计算一个优先级分数,当作业收到的时间分数小于最佳分配时,该分数会很高。调度是轮流进行的;在每一轮中,调度程序以优先级递减的顺序运行作业,同时确保给定作业不会在给定轮次中安排在多个工作程序(或加速器)上。这在图 5 中显示。优先级在轮次完成时更新。我们根据经验发现,大约 6 分钟的回合持续时间允许 Gavel 有效地接近理想分配(§7.5)。
吞吐估算器
为了估计并发作业的吞吐量(例如,在空间共享的情况下),Gavel 使用了一个吞吐量估计器,类似于 Quasar [21] 等先前工作中发现的那些。 Gavel 的吞吐量估算器将新作业映射到一组预先配置的参考作业。然后可以将最接近的参考作业的吞吐量用作新作业组合的初始性能估计。对于单个作业,不需要吞吐量估算器,因为当作业在不同的资源类型上运行时,可以动态估算吞吐量。
局限性与非目标
虽然 Gavel 公开了一个支持各种策略和目标的灵活 API,但我们并未在这项工作中提出新的调度策略或性能优化。相反,Gavel 的主要目标是确定如何以异构感知的方式最好地在许多不同的用户和作业之间共享资源,同时支持许多现有的集群范围的目标。 Gavel 通过一个策略框架来实现这些目标,该框架可以轻松地使策略具有异质性、共置和位置感知(§4)、可重用的调度机制(§5)以及允许用户部署他们的窄调度程序 API代码更改最少的应用程序 (§6)。