
基于深度学习的机器学习集群的任务放置
这是一篇发表在INFOCOM'2019上的论文, 特点是使用了强化学习进行任务放置。
Abstract
背景
- 虽然作业之间的服务器共享提高了资源利用率,但位于ML 作业之间的干扰可能会导致性能显着下降。
- 现有的集群调度程序(例如,Mesos)在其作业布置中是忽视干扰的,导致资源效率不佳。
- 干扰感知工作安置已在文献中进行了研究,但使用详细的工作负载分析和干扰建模进行了处理,这不是通用的解决方案。
Harmony
- 这是一种深度学习驱动的 ML 集群调度程序,它以最小化干扰和最大化性能(即训练完成时间)的方式放置训练作业。
- Harmony 是基于一个精心设计的深度强化学习(DRL)框架,并辅以奖励建模。
- DRL 采用了最先进的技术来稳定训练和提高收敛性,包括行为者-批评算法、任务感知行为空间探索和经验重放。
- 鉴于普遍缺乏对应于不同放置决策的奖励样本,我们建立了一个辅助奖励预测模型,该模型使用历史样本进行训练,用于为看不见的放置产生奖励。
实验
- 在 6 台 GPU 服务器的 Kubernetes 集群中使用真实 ML 工作负载进行的实验
- Harmony 在平均作业完成时间方面优于代表性调度程序 25%。
Introduction
任务干扰来源
- 许多现有的集群调度器倾向于超额分配,比如 CPU 和内存等资源,以最大化资源利用率(假设并非所有作业在任何时候都完全使用所需的资源)。
- 作业还共享底层资源,如 CPU 缓存、磁盘 I/O、网络 I/O 和总线(例如 QPI、 PCIe)。
- 例如,当服务器上的图形处理器卡被分配到不同的机器学习作业时,当作业在它们分配的 CPU 和图形处理器之间洗牌数据时,PCIe 总线被共享;
- 当两个分配的图形处理器没有连接到同一个非均匀访存模型体系结构中的 CPU 时,QPI 总线被共享。
不同类型任务之间的资源争用
- 一些机器学习任务是 CPU 密集型的,例如 CTC [7] ;
- 一些是磁盘 I/O 密集型的,例如 AlexNet [8] ,因为需要读取图像进行预处理;
- 还有一些由于模型大小(参数数量)和小批量(导致工人之间更频繁的参数交换) ,例如 VGG-16[9] ,网络带宽消耗水平很高。
将干扰程度较低的工作放在一起以优化性能是一个自然的想法。
现有调度器很大程度上是忽视干扰,这主要是由于难以获得许多作业的潜在干扰级别。
考虑干扰的工作
- 许多工作展示了干扰感知调度的潜力和有效性
- 考虑 MapReduce 作业中的网络争用
- HPC 作业的缓存访问强度。
- 这些研究基于某些观察/假设建立了目标性能的显式干扰模型,并依靠手工设计的启发式方法将干扰纳入调度。
- 他们通常需要在数十个干扰源下进行详细的应用程序分析,并相应地仔细优化性能模型中的系数或启发式中的阈值。
- 许多工作展示了干扰感知调度的潜力和有效性
痛点:通用性是这些白盒方法的一个问题:当工作负载类型或硬件配置发生变化时,启发式方法可能无法正常工作。
Harmony:一种黑盒方法,考虑干扰的同时,无需详细的性能建模
- 发现了ML工作负载之间共享资源时严重的性能下降, 提出了使用DRL来调度工作负载,自适应变化
- 采用了很多训练技术以确保DRL收敛到合适的放置策略, 包括actor-critic algorithm, job-aware action space exploration, experience replay。 建立了一个辅助的奖励预测模型, 用于为看不见的放置产生奖励。
- 在k8s上实现了原型, 实验评估发现, harmony比普遍策略性能高出25%
系统概述
- 提交一个ML任务,用户需要提交以下信息:
- 运行worker和PS的资源需求
- 使用的worker和PS的数量
- 训练数据集的epoch数
- 每个作业的worker和参数服务器的布置在整个训练过程中都不会改变
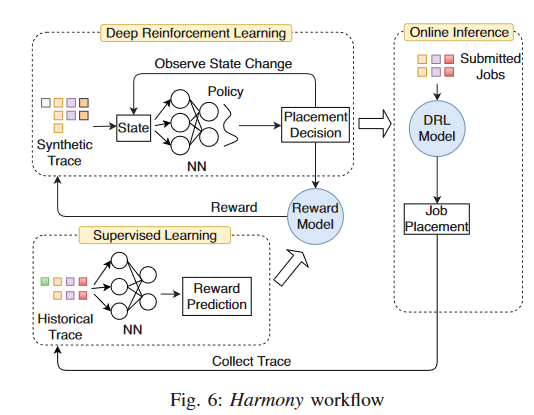
- 工作流程:
- 提交job,使用DRL模型, 得到放置决策
- 收集放置任务后的Trace, 进行有监督学习,预测奖励,得到奖励预测模型
- 使用奖励预测模型生成训练样本, 结合一系列State, 通过决策训练网络得到放置决策, 形成反馈
- 定期更新DRL模型
离线训练
使用纯粹的在线训练效果很差, 所以需要提前进行离线训练。离线训练共分为两步
- 奖励模型训练
- 通过历史工作轨迹,Harmony 使用监督学习训练奖励预测神经网络。
- 输入包括作业集信息和放置状态;标签是每项工作的奖励(训练速度)。
- 该模型通过相应的安置决策为任何工作集提供快速奖励评估。
- DRL模型训练
- DRL NN 将各种作业集和集群资源可用性作为输入,并为该集中的新作业生成放置决策。
- 通过奖励预测模型,我们可以有效地扩展了可用trace set并为 DRL 训练生成足够的样本。
在线推理和模型更新
- 在每个调度间隔中,Harmony 通过对 DRL NN 的推理来决定新作业批次的放置,并观察与放置决策相对应的实际奖励。
- 我们使用在线收集的样本定期重新训练 DRL NN 和奖励 NN,以随着时间的推移不断改进决策。
基于深度强化学习的任务放置
DRL框架
- 状态空间 s = (x, r, w, p, v, d)
- x:是任务n模型的独热编码。具有相同架构和批量大小的DNN被认为是同一种模型。
- r:是一个2(1+K)维的向量,编码worker和PS的资源需求。其中K是组成一个worker或PS的资源类型的数量。第一个值代表任务n需要的worker的数量,下K个值表示每个worker的K种资源的需求,剩余的1+K个值表示PS的数量及其资源需求。对于All-Reduce架构来说,将PS的资源需求置为0即可。
- w, p:一个整数,表示分配给任务n的worker和PS的数量。
- v:一个M*K的矩阵,表示每个服务器上每种资源的可用数量,M是物理服务器的数量
- d:一个M*2N大小的向量,编码任务n的worker和PS在服务器上的放置。
- 动作空间:依据s和policy $\pi(s, a)$ 选择相应的动作a
- 使用一个神经网络进行policy的训练
- 空间大小为2MN’, N’是新到的任务数
- (n, 0, m)表示服务器m给任务n分配一个worker
- (n, 1, m,)表示分配一个PS
- 奖励
- 目标是最小化平均任务完成时间
- 但是任务完成时间需要完成任务才知道
- 所以使用的是速度的求和, cn表示间隔内的已训练epoch, en是设定的总的epoch
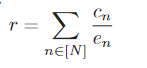
image-20230104124524937
- NN Model
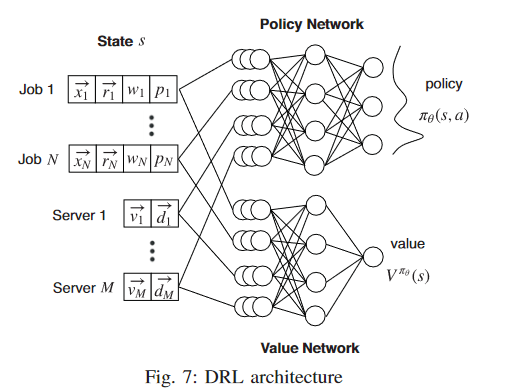
image-20230104120548893 - 每个作业或每个服务器的状态分别连接到一个全连接层,然后在输出层之前连接到几个全连接层。
- 这样,NN 可以从每个作业或每个服务器中提取特征,然后再合并为一个整体。
- 为了尊重服务器资源容量,在 NN 的输出层,我们通过在策略分布中将其概率设置为 0 来屏蔽无效操作,然后我们重新调整所有动作的概率,使总和仍然等于 1。
DRL模型训练
- 我们使用强化学习来训练策略NN, 每一个样本都是一个四元组(s, a, r, s’)。(状态, 动作, 奖励, 更新后的状态)。
- 目标:最大化累计折扣奖励
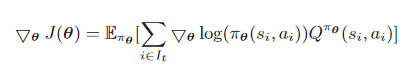
image-20230104125552347
- 训练技巧
- Actor-critic:基本思想是引入依赖于状态的基线函数,以改进 SGD 中用于更新策略 NN 的梯度。
- Exploration:确保充分探索行动空间, 以获得良好的Policy
- Experience replay: 使用连续样本训练 RL 模型很难收敛,采用经验回放来减轻样本序列中的相关性。
奖励预测模型
我们设计了一个奖励模型,可以预测给定作业和集群状态的奖励,我们可以基于该模型为 DRL 训练生成大量样本。
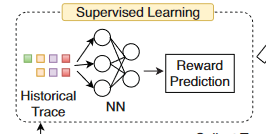
- NN 架构
- NN 的输入状态是 DRL NN 输入的子集:(x, w, p, d)。
- 输出的是预测的任务训练速度
- 并发作业中 worker 和 PS 的资源需求不包括在内,因为它们通常可以从作业的模型类型中推断出来。输出是一个向量,包括输入作业的预测训练速度输入状态连接到输出层之前的一系列隐藏的全连接层。
- 在实践中,我们发现与更复杂的神经层相比,全连接层在我们的场景中工作得很好。
- NN 训练
- 我们通过使用历史痕迹中的可用样本进行监督学习来训练 NN。
- 我们通过计算预测和标签的相对误差,将神经网络产生的每个作业 n 的预测训练速度 cn 与标签 c′n,即轨迹中每个作业 n 的训练速度进行比较。
- 然后我们使用 SGD 更新 NN 中的参数以最小化整体相对误差。
- 我们使用历史轨迹中的样本迭代地训练神经网络,使得神经网络产生的预测收敛于可接受的相对误差(例如 10%)。