HiveD: Sharing a GPU Cluster for Deep Learning with Guarantees
摘要
- 生产多租户集群中存在严重的共享异常现象
- 在这种情况下,一些租户中的作业所经历的排队延迟比它们在拥有其分配的 GPU 的私有集群中所经历的排队延迟更为严重。
- 这是因为租户使用配额(GPU 的数量)来保留资源,而深度学习作业通常使用具有理想 GPU 关联的 GPU,而配额不能保证这一点
- HiveD 是第一个安全共享 GPU 集群的框架,因此这种异常从设计上来说永远不会发生。
- 在 HiveD 中,每个租户通过虚拟专用集群(Virtual Private Cluster,VC)保留资源。
- 虚拟专用集群是根据集群中对应于不同级别的 GPU 亲和力的多阶储存细胞结构来定义的。
- 这种设计允许 HiveD 在每个 VC 中合并任何现有的调度程序,以实现各自的设计目标,同时安全地共享集群。
- HiveD 开发了一种优雅的伙伴细胞分配算法,
- 通过有效地管理来自 VC 的细胞与物理集群中的细胞之间的动态结合来确保共享安全。
- 伙伴细胞分配的直接扩展可以进一步支持低优先级作业,以清理未使用的 GPU 资源,从而提高集群利用率。
- 结合实际部署和跟踪驱动的仿真,我们发现
- (i)共享异常存在于三个最先进的深度学习调度器中,导致额外的队列延迟长达1000分钟
- (ii) HiveD 可以合并这些调度器,消除所有调度器中的共享异常,实现关注点分离,使调度器能够专注于自己的调度目标,而不违反共享安全。
引言
常见的做法
- 每个租户使用由 GPU 数量和其他相关资源(如 CPU 和内存)组成的配额来保留资源。
- 异常情况: DDL等待 GPU的时间明显长于在一个大小等于租户配额的私有集群中进行。
- 这是因为当前的资源预留机制是基于配额的,即 GPU 的数量。
- 配额不能捕获训练作业的 GPU 亲和性需求: 例如,一个节点上的8-GPU 作业通常比8个节点上的运行速度快得多。
- 配额不能像承租者的私有集群那样保证承租者的 GPU 关联性。
- 因此,多 GPU 作业通常必须在队列中等待或以放松的亲和力运行,这两种情况都会导致更差的性能(更长的队列延迟或更慢的训练速度)。
HiveD,一个共享 GPU 集群的资源预留框架,用于深度学习训练,通过完全消除共享异常来保证共享安全。
- HiveD 不使用配额,而是为每个租户提供一个由一个新的抽象: cell 定义的虚拟私有集群(简称 VC)。
- Cell 使用多级结构来捕获一组 GPU 可以满足的不同级别的亲和力。
- 这些细胞结构自然地在典型的 GPU 集群中形成一个层次结构;
- 例如,从单个 GPU,到连接到 PCIe 交换机的 GPU,到连接到 CPU 套接字的 GPU,到节点中的 GPU,再到机架中的 GPU,等等。
- HiveD 不使用配额,而是为每个租户提供一个由一个新的抽象: cell 定义的虚拟私有集群(简称 VC)。
Cell
- HiveD 将物理 GPU 集群虚拟化为每个租户的 VC,其中 VC 保留了物理集群中必要的亲和结构。
- 这使得任何一个最先进的深度学习调度器都可以在 VC 定义的边界内做出调度决策,而不会影响其他 VC 的亲和力需求,从而确保共享安全。
- 通过这种方式,HiveD 实现了关注点分离:它专注于资源预留机制,并将其他资源分配目标留给 VC 调度程序(例如,集群利用率和作业完成时间)。
- HiveD 将物理 GPU 集群虚拟化为每个租户的 VC,其中 VC 保留了物理集群中必要的亲和结构。
HiveD 开发了一种优雅高效的伙伴细胞分配算法,可以将细胞从 VC 绑定到物理集群。
- 伙伴细胞分配倡导动态细胞绑定,而非静态绑定,以获得灵活性。
- 它动态地创建和释放 VC 中的细胞到物理集群中的 GPU 的绑定,同时在不可预测的工作负载下提供经过验证的共享安全性。
- 此外,该算法可以自然地扩展到支持抢占的低优先级作业,以机会性地清除未使用的细胞,从而提高总体利用率。
- 结合起来,HiveD 实现了私有集群(保证独立于其他租户的细胞的可用性)和共享集群(在其他租户不使用资源时提高利用率和对更多资源的访问)的最佳性能
- 伙伴细胞分配倡导动态细胞绑定,而非静态绑定,以获得灵活性。
我们评估 HiveD 使用实验的96-GPU 实际集群和跟踪驱动的模拟。评估表明:
- 共享异常存在于所有评估的SOTA深度学习调度器中
- HiveD 消除了所有共享异常,将过度队列延迟从1000分钟减少到零,同时保留了这些调度器的设计目标;
- HiveD 保证了无论集群负载如何,都可以共享安全,而基于配额的集群可以导致高负载下租户的7倍过度队列延迟。
总之,本文作出了以下贡献:
- 我们是第一个观察和识别生产多租户 GPU 集群中共享异常的深度学习训练。
- 我们定义了针对异常的共享安全的概念,并提出了一种新的资源抽象,即多级细胞,用于建模虚拟专用集群。
- 我们开发了一个优雅和高效的好友小区分配算法来管理具有被证明的共享安全性的小区,并支持低优先级作业。
- 我们在一个实际的集群上进行了广泛的评估,并通过仿真,在产品跟踪的驱动下,表明 HiveD 在共享安全性、队列延迟和利用率方面达到了设计目标。
背景与动机
当前管理多租户 GPU 集群的方法。
- 在大型企业中,大型 GPU 集群通常由多个业务团队共享,每个业务团队都是贡献其资源(预算或硬件)的租户。
- 租户共享 GPU 集群的方式类似于共享 CPU 集群:
- 每个租户都被分配了许多令牌作为其配额。
- 每个令牌对应于使用 GPU 和其他类型资源的权利。
- 配额表示期望承租者能够“至少”访问其贡献的资源份额
- 租户共享 GPU 集群的方式类似于共享 CPU 集群:
- 为了提高集群中的培训速度
- 用户通常为深度学习任务指定 GPU 亲和力需求[52,86]。
- 例如,一个64-GPU 的作业通常需要以8 × 8的亲和力运行,即在8个节点上运行作业,每个节点使用8个 GPU,而不是64 × 1,即每个节点使用1个 GPU。
- 给定关联需求,资源管理器将以保证(硬)或最佳努力(软)的方式满足它们。
- 如果没有满足作业关联性要求的放置,则作业将在队列中等待亲和力要求,或如果要求是软性的(例如,64 × 1相对于8 × 8) ,则会以放松亲和力的方式安排。
- 用户通常为深度学习任务指定 GPU 亲和力需求[52,86]。
- 在大型企业中,大型 GPU 集群通常由多个业务团队共享,每个业务团队都是贡献其资源(预算或硬件)的租户。
共享异常
- 在生产 GPU 集群中,我们观察到用户投诉的异常情况:
- 一个租户被分配了64个 GPU 的配额,但是报告说它不能运行一个8 × 8深度学习作业。
- 原因:
- 这种异常现象之所以出现,是因为承租者所分配的亲和力已经被其他承租者的工作分割
- 结果
- 即使租户有足够的 GPU 配额,64-GPU 作业也必须在队列中等待,或者以放松关联的方式执行性能下降的作业。
- 向承租者保证它至少可以访问其所占的资源的承诺被打破了。
- 分析
- 如果我们将租户比作程序,那么共享异常看起来类似于内存管理中的外部碎片。
- 然而,重要的区别在于,在共享的 GPU 集群中,租户希望他们的资源共享得到保证
- 显然,配额只能保留资源的数量,而不能保留资源的亲和力。
- 在生产 GPU 集群中,我们观察到用户投诉的异常情况:
减少共享异常的一种方法是设计一种调度策略,以尽量减少全局资源分散。
- 这使得深度学习调度器的设计更加复杂,它已经需要管理复杂的多目标优化。
- 例如,最小化全局碎片化可能会由于工作间干扰的增加而降低工作绩效[86]。
- 因此,我们建议将共享异常的关注与其他资源分配目标分开[47]。
- 我们没有开发一个能够实现所有可能目标的复杂调度程序,而是设计了 HiveD,一个侧重于消除共享异常的资源预留框架
- 并提供了一个干净的界面,以纳入任何最先进的深度学习调度程序,以解决诸如集群利用率[86]、作业完成时间[41,66]和公平性[29,60]等问题
- 这使得深度学习调度器的设计更加复杂,它已经需要管理复杂的多目标优化。
HiveD设计
系统总览
- HiveD 提出保证消除共享异常,作为共享 GPU 集群的先决条件。
- 具体来说,如果可以在私有集群中满足具有亲和需求的 GPU 请求序列,那么应该在相应的虚拟私有集群和共享物理集群中满足这些请求序列。
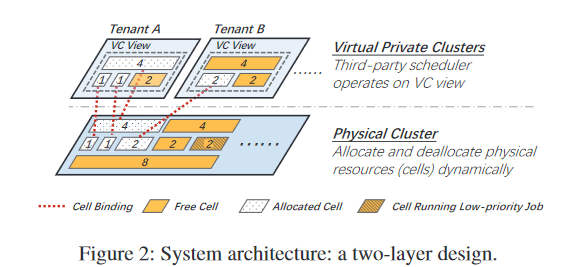
图2说明了整个系统架构。
- HiveD 对 GPU 资源的抽象分为两层
- 虚拟专用集群(VCs)层
- 物理集群层
- HiveD为每个租户提供一个 VC。
- 每个 VC 都预先分配了一组细胞格,这是一种新的资源抽象不仅捕获配额,而且捕获 GPU 的亲和结构(图中每个细胞内的数字显示细胞的亲和 GPU 的数目)。
- 分配给 VC 的细胞形成一个 VC 视图,其 GPU 亲和结构与相应的私有集群相同。
- 任何第三方调度程序都可以合并到 VC 视图中,以实现一定的资源分配目标。
- 此外,HiveD 保证任何调度决策都被限制在 VC 视图定义的边界内,就像在它的私有集群上发生一样,从而保证了共享的安全性。
- HiveD 对 GPU 资源的抽象分为两层
VC 中的细胞是逻辑的
- 当作业在逻辑细胞中使用 GPU 时,
- 例如,图2中 Tenant A 的 VC 视图中的4-GPU 细胞中的一个 GPU,逻辑细胞将绑定到从物理集群分配的物理细胞,如图2底部所示。
- 如果没有使用任何 GPU,则逻辑细胞将从物理集群解除绑定。
- 为了提高利用率,可抢占的低优先级作业可以机会性地清除空闲的 GPU。
- 这种动态绑定比静态绑定更加灵活:
- 动态绑定可以避免硬件故障的物理细胞
- 它可以避免低优先级作业使用的细胞以减少抢占
- 它还可以包装细胞以最小化 GPU 亲和力的碎片
- 这种动态绑定比静态绑定更加灵活:
- 当作业在逻辑细胞中使用 GPU 时,
为了实现这一点,HiveD 采用伙伴细胞分配(一种高效而优雅的算法)来处理动态绑定。
- 动态绑定的一个关键挑战是保证响应动态工作负载的安全性,即作业不可预测地到达并请求不同级别的细胞。
- 证明了伙伴细胞分配算法能够保证共享的安全性:
- 在 VC 中任何合法的细胞请求都能够得到满足。
- 该算法还可以支持低优先级作业。
- 图2显示了一个可能的细胞分配,其中物理集群中的细胞绑定到两个 VC 中定义的细胞,并且还绑定到一个低优先级作业。
细胞结构的虚拟私有集群
- 为了建模一个(私有的)图形处理器集群,HiveD 定义了一个多阶储存细胞结构的层次结构。
- 一个细胞在某个级别上是相应的关联 GPU 集合,它们具有互连拓扑。
- 然后将每个虚拟私有集群(VC)定义为每个级别上的细胞数,并以相应的私有集群为模型。
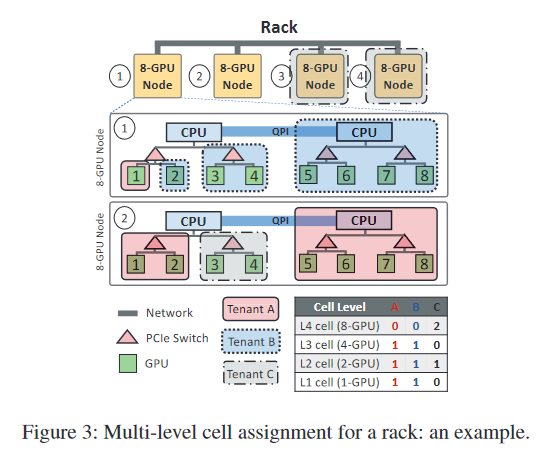
图3显示了一个示例
- 其中有4个级别的细胞结构:
- 1:GPU
- 2:PCIe 开关
- 3:CPU 套接字
- 4:节点级别
- 集群有一个机架,由四个8-GPU 节点组成,由三个租户 A、 B 和 C 共享。
- 图3中的表格总结了每个租户的 VC 的细胞格分配。
- 租户 A 和 B 的 VC 都保留一个第3级细胞(同一 CPU 套接字下的4个 GPU) ,一个第2级细胞(同一 CPU 套接字下的2个 GPU PCIe 开关)和一个1级细胞(单个 GPU)。
- 租户 C 是一个较大的租户,它保留两个4级细胞(节点级)和一个2级细胞。
- 给定图3中定义的 VC 视图,HiveD 可以采用第三方调度程序来处理视图。
- 从第三方调度器的角度来看,VC 视图与由不同大小(即不同细胞级别)的节点组成的私有集群没有什么不同。
- 例如,调度程序可以将租户 C 视为一个私有集群,其中包含两个8-GPU 节点和一个2-GPU 节点,尽管2-GPU 节点实际上是一个2级细胞。
- 请注意,第三方调度程序可以使用分配细胞中的任何 GPU。
- 例如,它可以将两个2-GPU 作业调度到一个4-GPU (level-3)细胞: 细胞是 VC 和物理集群中资源预留的粒度,但不一定是第三方调度程序的作业调度粒度。
- 从第三方调度器的角度来看,VC 视图与由不同大小(即不同细胞级别)的节点组成的私有集群没有什么不同。
- 图3中的表格总结了每个租户的 VC 的细胞格分配。
- 其中有4个级别的细胞结构:
在细胞格层次结构中,一个级别 k 细胞格 c 由一组级别(k-1)细胞格 S 组成。
- S 中的细胞格称为伙伴细胞格; 伙伴细胞格可以合并到下一个更高级别的细胞格中。
- 我们假设细胞格具有分层的统一可组合性
- (i)所有级别 k 细胞格在满足租户对级别 k 细胞格的请求方面是等价的,
- 并且(ii)所有级别 k 细胞格可以分割成相同数量的级别(k-1)细胞格
异质性。
- 一个异构集群可以划分为多个具有层次一致可组合性的同构集群。
- 这在实践中是合乎逻辑的,因为一个产品集群通常由足够大相同的子集群组成
- 为了获得更好的性能,用户通常使用同质的 GPU,并指定所需的 GPU/拓扑类型
初始细胞分配。
- 集群提供者必须计算出在每个级别上分配给每个租户的 VC 的细胞数。
- 如果 VC 分配能够容纳分配给所有 VC 的所有细胞,那么 VC 分配在物理集群中是可行的;
- 也就是说,存在从每个 VC 中的逻辑细胞到物理集群中的物理细胞的一对一映射。
- 最初的细胞VC 的分配取决于预算、业务优先级和工作量等因素,因此它是在 HiveD 之外处理的
- 集群可能比分配的细胞节省更多的物理资源来处理硬件故障。
- 集群提供者必须计算出在每个级别上分配给每个租户的 VC 的细胞数。
伙伴细胞分配算法
HiveD 管理 VC 中的逻辑细胞和物理集群中的物理细胞之间的动态绑定,并处理分配和释放细胞的请求。
- 这是由好友细胞分配算法完成的。
- 该算法为每个 VC 维护以下信息:
- (i)每个分配的逻辑细胞对应的物理细胞(即绑定) ;
- (ii)每个细胞级别 k 的全局空闲列表,以跟踪该级别的所有未分配的物理细胞。
- 该算法始终将可用细胞保持在尽可能高的级别:
- 例如,如果级别-(k-1)的所有伙伴细胞都可用于级别-k 的细胞,则只记录级别-k 的细胞。
- 该算法旨在保持尽可能多的高级细胞可用。算法1显示了算法的伪代码。
- 该算法始终将可用细胞保持在尽可能高的级别:
为了在 VC 中分配一个 level-k 细胞,算法从 level-k 开始,如果需要则向上分配:
- 它首先检查一个空闲 level-k 细胞是否可用,如果可用则分配一个。
- 如果没有,算法将一级一级地向上移动,直到有一个空闲的级别 -l 细胞可用,其中 l > k。
- 然后,该算法将递归地将一个空闲的1级细胞划分为多个低级细胞,直到有一个 k 级细胞可用。
- 每次分割都会在下一个较低级别产生一组好友细胞格,这些好友细胞格将被添加到该较低级别的空闲列表中。
- 其中一个新的低能级细胞再次分裂,直到产生游离的 k 能级细胞。
细胞释放过程也是以自底向上的方式进行的。
- 当释放一个 level-k 细胞格 c 时,算法将 c 添加到检查 C 的好友细胞的状态。
- 如果 c 的好友细胞格都是空闲的,那么算法将把 c 和它的好友细胞格合并到一个级别为(k + 1)的细胞格中。
- 合并过程在上升级别时递归地继续,直到没有细胞格可以合并为止。
- 这样,好友细胞分配算法减少了 GPU 碎片,并创建了调度需要更高级别细胞的作业的机会。
在处理分配请求之前,算法确保请求是合法的,因为它在这个细胞级别的 VC 的分配配额内。HiveD 将细胞格分配存储在一个表 r 中,其中一个租户 t 为 level-k 细胞格预先分配的编号存储在 rt,k 中。伙伴小区分配算法保证在一个可行的初始 VC 分配下满足所有合法小区的请求,这在定理1中有正式描述。
定理1。在层次一致可组合的条件下,如果原来的 VC 分配是可行的,那么伙伴细胞分配算法可以满足任何合法的细胞分配。