
摘要
背景
- 为了加速深度学习(Deep Learning,DL)模型的培训,使用配备 GPU 等硬件加速器的机器集群来减少执行时间。
- 需要最先进的资源管理器来提高 GPU 的利用率和最大化吞吐量。
- 虽然在同一 GPU 上共享 DL 作业已被证明是有效的,但这可能会引起干扰,从而导致速度减慢。
Horus: 一个用于 DL 系统的干扰感知和基于预测的资源管理器。
- Horus 主动预测了从 DL 模型的计算图特征推断出的异构 DL 作业的 GPU 利用率,从而消除了在线剖析和隔离保留 GPU 的需要。
- 通过跨异构 GPU 硬件的微基准测试和工作共享
- 我们将 GPU 利用率确定为一个通用的代理度量,以确定良好的安置决策
- 与目前的方法相反,去除了GPU在线剖析,不直接测量每个提交的工作的 GPU 利用率。
- 我们的方法促进了高资源利用率和完成时间的减少; 通过真实世界的实验和大规模的跟踪驱动模拟,我们证明
- Horus 在 GPU 资源利用率方面优于其他 DL 资源管理器高达61.5%
- 在完成时间减少方面优于23.7-30.7%
- 在作业等待时间减少方面优于68.3%
引言
- 由于现有的资源管理器,如 Kubernetes和 YARN禁止明确使用 GPU 共享(即,只允许将单个 DL 作业分配给每个 GPU)。
- 这种利用率不足降低了性能、资源效率和服务可用性
- 导致排队时间延长
- 需要额外的 GPU 设备来满足需求
- 共享GPU已经成为解决利用率不足的一种方法
- 这种共存位置的有效性基于对 DL 工作负载 GPU 利用模式的良好理解
- 对于提供商来说,这可以实现高质量的 DL 系统调度和同位置决策。从而减少 GPU 资源利用不足的情况。
- 了解和利用 DL 工作负载利用率来改善同一地点对于设计资源节约型 DL 系统至关重要
- 但是,通过 DL 工作负载描述 GPU 利用率的已有方法在执行过程中利用了在线分析。
- 在线分析需要在独立的 GPU (或专用机器)上执行每个惟一的 DL 作业,以确保准确的度量收集[21] ,[22]。由于需要保留 GPU 设备,这种在线分析导致服务可用性和资源效率降低: 随着不同模型架构和配置数量的增加,这是一个日益严重的问题[8]。虽然同位可以提高 GPU 的利用率,但它也可能引起性能干扰(我们称之为干扰) ,导致不同同位组合的 DL 作业平均减速18% [8]。虽然 DL 资源管理器现在允许同位[6] ,[8] ,[10] ,但较少注意积极解决 DL 作业之间的干扰共享相同的 GPU 期间安置决定。差的 DL 工作安排导致更高的完成时间,增加的作业完成时间(JCT) ,作业驱逐,以及 GPU 内存不足(OOM)错误造成的作业失败[9]。
- 在本文中,我们提出了 Horus: 一个基于预测的干扰感知的 DL 系统资源管理器。与现有的方法相比,Horus 根据 DL 作业的模型特征主动预测 GPU 对未知 DL 作业的利用率,我们的调度器利用这些模型特征来确定合适的 DL 作业同位组合以最小化干扰。我们的方法避免了剖析内核模式[10] ,[13] ,[21] ,[22] ,修改底层 DL 框架,也不需要在调度器运行时需要一个孤立的 GPU 的作业执行的大量在线剖析ーー所有这些都是昂贵的和时间的
- 同一地点所造成的数据传输角色塑造工作量干扰。我们已经描述了超过600个跨异构 GPU 硬件架构的 DL 作业的独特组合的干扰概况。研究结果表明,DL 工作同位干扰导致2.4 x-3.4 x 的速度减慢,与分布式培训的网络局部性相当。
- DL 工作负载的 GPU 利用率分析与预测引擎。通过一系列的基准测试,我们分析和识别了 DL 模型的关键特性及其与 GPU 利用率的关系。其中包括每秒浮点运算(FLOPs)、输入数据大小和卷积层数目等 DL 计算图结构。我们提出的预测引擎允许分秒的 DL 作业 GPU 利用率预测,而不需要在线剖析。
- 支持干扰的 DL 资源管理器。利用我们的预测引擎,我们提出了一个支持协同定位和最小化 GPU 过度使用的干扰软件资源管理器。我们的方法提供了两种可供选择的调度算法,优先考虑最小化作业完成时间或提高公平性以避免作业匮乏ーー降低中位作业等待时间,代价是作业完成时间和利用率的边际降低。资源管理器被集成到 Kubernetes,部署在一个数字用户线集群中,并通过对一个生产数字用户线集群的跟踪驱动模拟进行大规模评估。结果表明,与现有方法相比,我们的方法在 GPU 集群利用率方面实现了32-61.5% 的增长,并且最多可以减少23.7-30.7% 的工作时间。
- 我们扩展了我们以前的工作[23] ,通过将 DL 工作负载角色塑造研究的范围从81个增加到292个模型,获取更多的图形处理器架构和600多个用于分析和建模的同位概况,提高图形处理器预测模型的准确性,并通过追踪驱动的生产集群模拟来评估 Horus 的规模。Horus 框架也进行了重新设计,包括一个精确的公平排队调度算法,以最小化成本目标。最后,通过一组额外的工作负载组合和一个额外的共同定位算法进行了评估,以进行比较[8]。
动机
背景
DL 利用率与推理
CO-LOCATION关系研究
剖析设定
GPU利用率与JCT减缓的关系
Horus
- Horus 是一个基于预测的、支持干扰的 DL 系统资源管理器,它被设计成一组组件,可以作为现有集群资源管理器框架(如 Kubernetes)的一部分部署。
- 图5描述了 Horus 架构,它包括三个主要组件:
- 预测引擎
- 度量库
- 应用程序控制器。
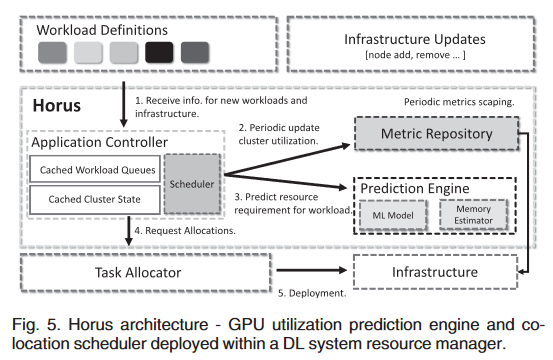
image-20230515124449778 - 预测引擎
- 在作业提交时,应用程序控制器通过检查工作负载定义向预测引擎发送一个请求,以估计 DL 作业 GPU 的使用情况,即 GPU 利用率和 GPU 内存利用率。
- 具体来说,预测引擎需要一种访问 DNN 图并模拟运行模型的方法
- 度量库
- 集群视图通过基础设施更新和监控代理来维护,从每个节点收集基础设施数据,包括 GPU 使用情况和系统使用情况(主机内存使用情况和 CPU 使用情况)。
- N 个代理部署在每个单独的节点上,报告应用程序和系统利用率指标,这些指标最终被收集到度量存储库中。
- 应用控制器
- 然后,调度程序通过计算 DL 作业的适用性将其分配给 GPU ーー最小化成本函数目标,以支持同地共存的 缓存集群状态。
- 我们的方法旨在最大限度地提高 GPU 的利用率,并通过降低同一地点放置决策的优先级来最小化完成时间,这将导致严重的干扰和通信延迟导致 JCT 减速(第4.2节)。
- 图5描述了 Horus 架构,它包括三个主要组件:
预测引擎
预测GPU利用率
- 总览
- 预测引擎通过迭代 DL 模型的开放神经网络交换(ONNX)图表表示来提取表3中描述的关键 DL 工作负载特征。我们可以通过迭代每个运算符,并根据其输入、输出形状和参数进行计算,获得 FLOP 等聚合特征。
- 然后将特征标准化并用作机器学习模型的数字输入,以预测 GPU 的利用率(GUtilj)。我们在离线培训阶段基于一组历史 DL 工作负载概况微基准来训练预测模型,类似于现有的基于预测的方法[14] ,[29]。这些配置文件通常是通过运行微基准测试的开发人员获得的,或者是通过监视孤立 GPU 上现有的非共存 DL 工作负载获得的。
- 至关重要的是,在成功的预测模型训练之后,不需要为进入系统的唯一 DL 工作负载进行隔离剖析。值得注意的是,这种方法也可以与反应性方法[8] ,[10] ,[15] ,[17] ,[18]相结合。机器学习模型可以在收集了额外的配置文件(例如,当发现新的模型)之后周期性地重新训练。
- 特征重要性
- 为了进一步了解是什么促进了 GPU 的利用,我们调查了每个基于树的回归特征权重,通过提取权重和平均它们,如图6所示。
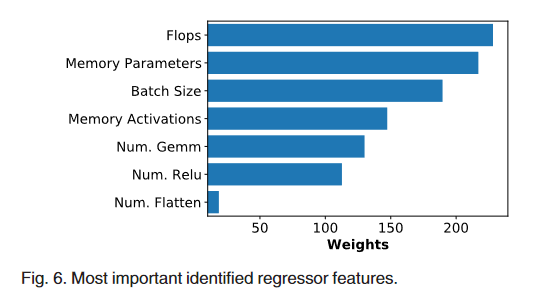
image-20230515125327336 - 这些特性是明确的指标,并遵循现有的模型压缩和神经结构搜索的文献,其中减少参数和中间激活的数量可以节省硬件的计算和内存消耗[37] ,[45]。令人惊讶的是,我们发现卷积的数量和剩余的特性对回归器的影响很小,甚至没有影响,我们计划利用编译器中间表示来获得更多的硬件特性特征[25]。
- 模型评估
- 模型的准确性是通过测量回归平方平均数对数误差(RMSLE)来确定的。
- 这种方法对于利用率预测是有用的:
- 虽然高估 GPU 利用率在最大化资源效率方面并不理想
- 但是低估可能导致意外的 GPU 过度分配和我们试图避免的干扰
- 表4显示,所有的预测模型实现了相对较低的 RMSLE 得分为0.133。
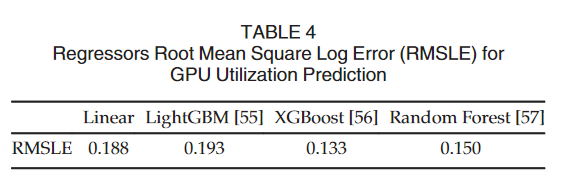
image-20230515125313318
预测GPU内存利用率
与 GPU 利用率相比,估计 GPU 内存利用率更为复杂,因为总的作业内存大小(MiB)受各个 DL 库的初始化和优化控制。在不研究内核实现的情况下,可以通过考虑正向 Mf 和反向传递 Mb 中的以下四个因素来估计最小预期内存使用量(以字节为单位) : (i)数据 B 的批量大小,(ii)激活次数 A,(iii)梯度 G 的数量和(iv)参数 P 的数量。除了初始化开销 d 之外,给定 DL 作业 j 的总体估计内存需求将是
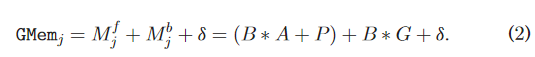
GPU 利用率(GUtilj)和 GPU 内存(GMemj)估计值将用于调度器中的节点容量检查,以防止处理传入作业。
推理感知的任务调度
Gandiva [8]布局策略监控应用程序吞吐量,当使用未定义的阈值和时间段进行减速检测时,一个作业被随机杀死或迁移到另一个节点。在这种方法中,随机作业迁移可能被分配到另一个不兼容的作业,从而导致相同或更大的性能下降。
Antman [10]通过监视 DL 作业,雇用本地协调器和修改底层 DL 框架来实现共同定位,以允许对 DL 作业内核进行细粒度控制,在 GPU 上注入空闲时间以减轻共同定位作业之间的干扰。然而,这种方法需要理解和分析内核在运行时的执行顺序,以确定适当的空闲时间。我们的干扰感知调度的核心是在作业执行之前了解计算资源需求,并以尽可能少的成本为作业分配相应的资源。这与现有的 DL 系统调度程序形成对比,后者在获得工作负载利用模式之后作出反应。
任务调度计划
- 问题建模
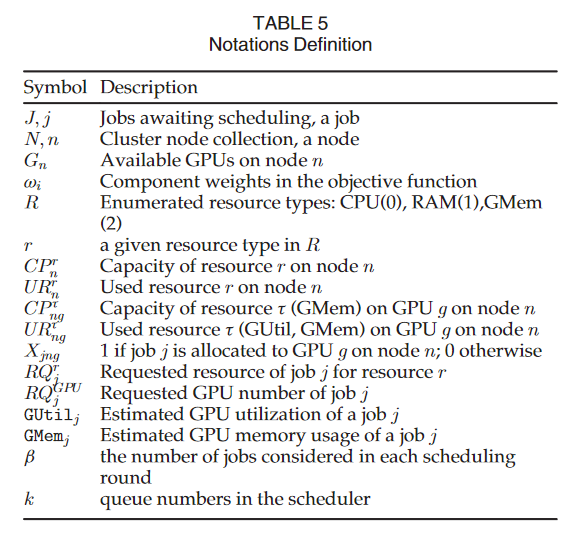
image-20230515130031081 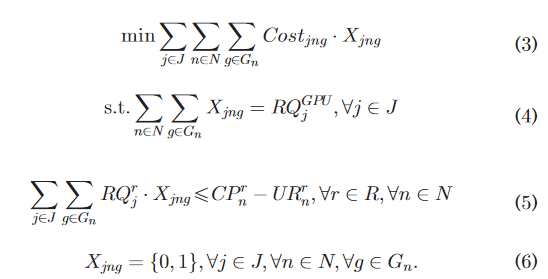
image-20230515125939659
- 成本明细
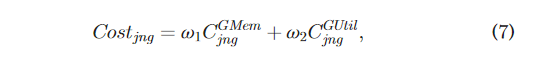
image-20230515125953903 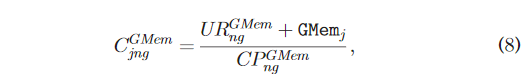
image-20230515130047005 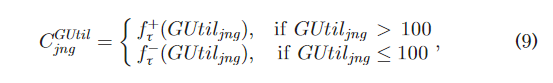
image-20230515130058309 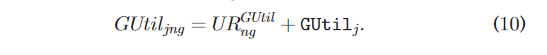
image-20230515130130804
基于有权公平队列的运行时作业调度

- 作业聚合
- 在实际调度作业之前,我们对所有作业执行一个聚合过程。具体来说,L1距离度量用于鉴别类似的工作,考虑到以下特征:
- (1)任务数量
- (2)预测的 GPU 利用率
- (3)每个任务的 GPU
- (4)估计的 GPU 内存
- 在实践中,我们对所有待执行作业运行 k-means 算法来识别相似的作业,并将它们放入相应的队列,即 Q1.41.Q1; … ; Qk (第2行)。
- 我们设置 k = 3,因为我们发现,从图1a,利用模式有3个不同的 CDF。
- 在实际调度作业之前,我们对所有作业执行一个聚合过程。具体来说,L1距离度量用于鉴别类似的工作,考虑到以下特征:
- 基于加权公平排队的作业选择
- **line 4:**基于加权公平排队的作业选择。据推测,b 作业被允许作为批处理进入每个调度周期。公平地说,horus拿起一定数量的未决根据队列权重从每个队列中删除作业,即作业挂起的程度。
- 我们期望从等待时间更长、队列长度更大的队列中选择和处理更多的作业,
- 我们测量作业的每个队列的中值等待时间和队列长度的乘积的权重,其中最大运算是为了保证一个非零值一旦中值等待时间为零时,所有作业都是新到达系统。
- 中值具有统计特性,受偏斜数据的影响较小,可以更准确地反映一类作业的排队时间。
- 最后,计算从 Qx 中选择的作业数。
- 这种设计可以积极地避免任何特定类别的工作饥饿——当某个类别的工作开始饥饿时,将会选择更多的工作。我们还允许对饥饿作业进行预留,因为加权公平排队算法会选择等待时间最长的作业。
- 我们测量作业的每个队列的中值等待时间和队列长度的乘积的权重,其中最大运算是为了保证一个非零值一旦中值等待时间为零时,所有作业都是新到达系统。
- 资源分配
- 由于所有待完成的任务都按照加权公平性排序到 e J 中,因此调度器将尽最大努力为每个任务分配可用资源,同时将性能干扰降到最低。
- **line 8:**具体来说,对于每个作业,我们检查资源容量, 并且选择所有可以满足作业 j 在 CPU、内存和 GPU 内存方面的所有需求的节点。
- **line 9-12:**GPU 内存需求是通过方程推断出来的。(2)第4.1条。基于作业所需的 GPU 总数和每个节点的 GPU 数,我们计算出满足作业 j 需求的最小节点数
- line 14: 用方程式(7) ,然后我们可以计算在 N (第14行)中每个节点的每个 GPU 上调度作业的成本
- line 16: 以最小的成本(第16行)选择顶部的 GPU (G)。
- line 18: 并在最终资源分配和作业调度(第18行)