
Tiresias 论文阅读笔记
Abstract
- 深度学习 (DL) 训练作业给现有的集群管理器带来了一些独特的挑战,例如
- 不可预测的训练时间
- 全有或全无的执行模型
- GPU 共享的不灵活性
- 我们对生产中的大型 GPU 集群的分析表明,现有的大数据调度程序会导致
- 较长的排队延迟
- 较低的整体性能
- 我们介绍了 Tiresias
- 这是一个为分布式 DL 训练作业量身定制的 GPU 集群管理器,它可以有效地安排和放置 DL 作业以减少它们的作业完成时间 (JCT)。
- 鉴于 DL 作业的执行时间通常是不可预测的,我们提出了两种调度算法——
- 离散化二维Gittins索引:基于部分信息
- 离散化二维 LAS: 与信息无关,旨在最小化平均 JCT
- 此外,我们描述了何时可以放宽合并放置约束,并提出了一种放置算法来利用这些观察结果而无需任何用户输入。
- 在具有 60 个 P100 GPU 的密歇根 ConFlux 集群上进行的实验和大规模跟踪驱动模拟表明,
- 与生产中使用的基于 Apache YARN 的资源管理器相比,Tiresias 将平均 JCT 提高了 5.5 倍。
- 更重要的是,Tiresias 的性能与假设完美知识的解决方案的性能相当。
Introduction
由于 DDL 训练的独特限制,我们观察到当前集群管理器设计中的两个主要限制。
- 训练时间不可预知的朴素调度
- 尽管已知最短作业优先 (SJF) 和最短剩余时间优先 (SRTF) 算法可以最小化平均 JCT ,但它们需要作业的剩余执行时间,而这对于 DL 训练作业来说通常是未知的.
- Optimus可以依靠其重复执行模式并假设其损失曲线会收敛来预测 DL 训练作业的剩余执行时间。然而,这些提议对具有平滑损失曲线和运行完成的工作做出了过于简化的假设;在生产系统中,两者都不总是正确的。
- 正因为如此,生产中最先进的资源管理器相当天真。例如,微软内部的解决方案是从 Apache YARN 最初为大数据作业构建的 Capacity Scheduler 扩展而来的。它只执行基本的编排,即作业到达时的非抢占式调度。因此,当集群超额订阅时,用户经常会遇到长时间的排队延迟——即使是小作业也可能长达数小时。
- 放置任务过程中过度激进的合并
- 现有的集群管理器还试图将 DDL 作业整合到具有足够 GPU 的最少数量的服务器上。例如,一个有 16 个 GPU 的作业在每台服务器 4 个 GPU 的集群中至少需要四台服务器,如果找不到四台完全空闲的服务器,作业可能会被阻塞。
- 基本假设是应尽可能避免使用网络通信,因为它可能成为瓶颈并浪费 GPU 周期 。然而,我们发现这个假设只是部分有效。
在本文中,我们提出了 Tiresias,一种共享 GPU 集群管理器,旨在解决上述有关 DDL 作业调度和放置的挑战。为确保Tiresias实用且易于部署,我们依靠对生产作业轨迹的分析、对训练各种 DL 模型的详细测量以及两个简单而有效的想法。此外,我们有意让 Tiresias 对用户保持透明,即所有现有作业都可以在没有任何额外的用户指定配置的情况下运行。
- 第一个想法:一个新的调度框架(2DAS),旨在在 DL 作业的执行时间不可预测时最小化 JCT
- 调度算法
- Discretized 2D Gittins index
- Discretized 2D-LAS
- 上述两个方案都是给任务一个优先级,前者使用Gittins索引,后者直接应用收到的任务(随着时间会改变,任务会按照优先级来进行调度)
- 使用上述策略有两个挑战
- 计算任务优先级的时候。需要同时考虑空间和时间两个维度。空间:GPU个数, 时间:任务运行时间。
- 相对优先级可能会随着工作接受服务二发生变化, 可能会导致工作被抢占, GPU抢占DDL工作的代价昂贵, 所以为了避免抢占, 作业的优先级需要在固定的时间间隔发生变化。
- 有先验的情况下使用Gittins索引, 没有先验的情况下使用LAS
- 调度算法
- 第二个想法:尽可能使用模型结构来放松合并放置约束
- 我们观察到只有某些类型的 DL 模型对其是否合并敏感,并且它们的敏感性是由于其模型中张量大小分布的偏差。我们使用这种洞察将工作分为两类:
- 对整合敏感(高偏差)的工作
- 其他工作
- 我们在 Tiresias 中实现了一个 RDMA 网络分析库,它可以通过网络级活动确定 DDL 作业的模型结构。
- 通过利用分析库和 DDL 训练的迭代特性,Tiresias 可以透明且智能地放置作业。
- Tiresias 首先在试用环境中运行作业几次迭代,然后根据从先前测量中总结的标准确定最佳放置策略。
- 我们观察到只有某些类型的 DL 模型对其是否合并敏感,并且它们的敏感性是由于其模型中张量大小分布的偏差。我们使用这种洞察将工作分为两类:
本文的贡献如下:
- Tiresias是第一个信息不可知的GPU集群资源管理器。同时也是第一个使用了两个维度的扩展和优先级来调度DDL工作。
- 使用了一个简单的, 外部可观察的, model-specific的评价标准来判断什么时候放松GPU合并的约束
- 设计简单,易部署, 性能显著提高
背景和动机
DDL分布式深度学习
这里只关注数据并行
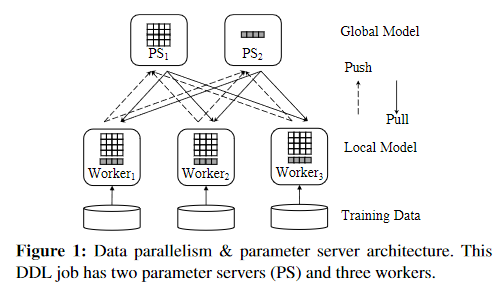
- 周期性迭代
- 参数服务器架构
- Trial and error 的探索: 超参数调优
挑战
- 不可预知的作业时间
- 当前预测 DL 作业训练时间的解决方案 都假设 DL 作业
- (1) 具有平滑的损失曲线
- (2) 达到其训练目标并完成
- 然而
- 对于许多在试错探索过程中较差的模型,它们的损失曲线并不像探索结束时最终选择的最佳模型的曲线那样平滑。如图2
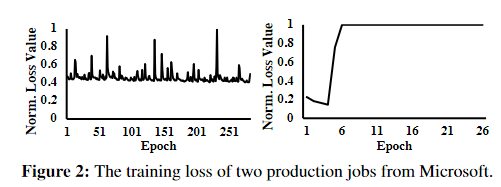
image-20221227123048934
- DL的终止条件是不确定的
- 对于许多在试错探索过程中较差的模型,它们的损失曲线并不像探索结束时最终选择的最佳模型的曲线那样平滑。如图2
- 因此,实际的资源管理器设计不应依赖于准确性/损失曲线来预测最终的作业完成时间。
- 当前预测 DL 作业训练时间的解决方案 都假设 DL 作业
- 过度激进的任务合并
- 在模型聚集阶段尝试减少网络的通信在分布式训练中是一种通用的优化,因为网络可能是性能瓶颈并且浪费GPU周期。
- 然而,许多现存的GPU管理在放置分布式深度学习任务时盲目地遵从一个合并约束,特别地,他们将作业的所有组件(参数服务器和Worker)分配给相同或最小数量的服务器
- 一个分布式深度学习作业如果不能合并通常会等待,即使集群中有足够的空闲资源,虽然这个约束是为了高性能,但是会导致更长的队列延迟和低的资源利用。
- 抢占式的时间开销
- 由于时间开销大,目前的生产集群并没有抢占作业。
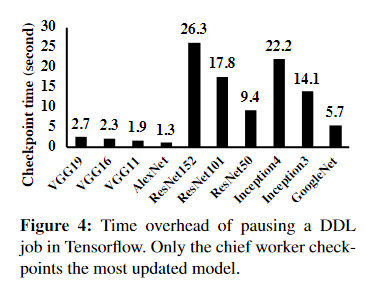
image-20221227124028866 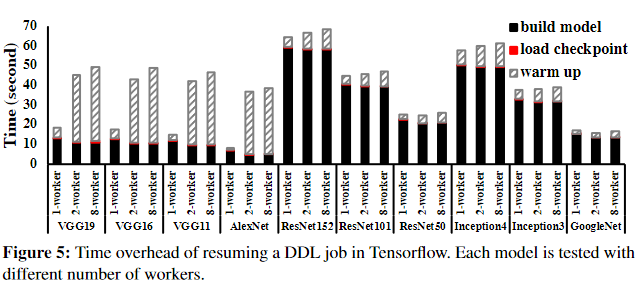
image-20221227124044585
潜在的收益
破除两个谬误, 可以获得巨大的提升
- 谬误一:如果没有确切的工作持续时间,就无法很好地安排工作。
- 尽管 DDL 作业持续时间通常是不可预测的,但可以从历史日志中了解它们的总体分布。
- 广泛用于解决经典多臂老虎机问题的 Gittins 指数策略,只要给定工作持续时间分布,就可以降低平均 JCT。
- 即使没有这些信息,LAS 算法也可以根据获得的服务有效地安排作业。
- 谬误二:DDL 作业应该始终合并。
- 虽然合并放置作业确实可以最大限度地减少其通信时间,但我们发现某些 DDL 作业对放置不敏感。
- 我们确定核心因素是模型结构
Tiresias 的设计
总体架构
- 调度目标
- 用户为中心:最小化平均JCT
- 操作者为中心:提高GPU的利用率
- 平衡以上二者:任务不能无限饥饿
- 一些假设
- 任务在线达到
- 任务持续时间未知
- 任务的任务特性未知
- All or Nothing的资源分配
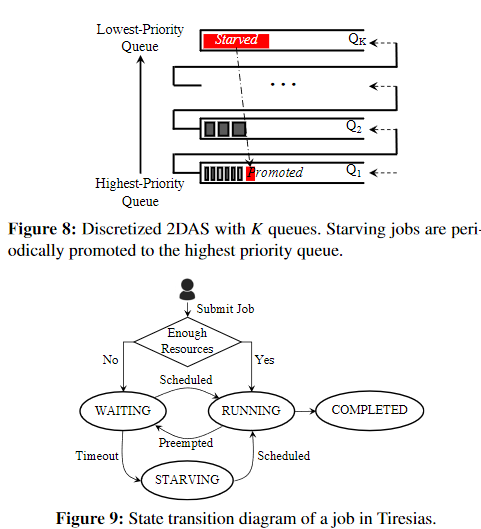
- 任务的生命周期
- Tiresias 旨在优化上述目标,而无需在特定 DL 框架下对作业的资源需求、持续时间或其内部特征做出任何假设。
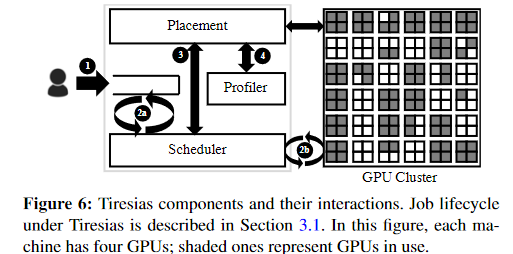
image-20221227125201039 - 图 6 展示了 Tiresias 的架构以及作业生命周期中发生的一系列操作。
- 1)作业一提交,其 GPU 要求就已知,并且它被附加到 WAITQUEUE 。
- 2)调度程序定期调度来自 WAITQUEUE 的作业,并在作业到达、作业完成和资源可用性变化等事件时抢占集群中正在运行的作业到 WAITQUEUE。
- 3)首次启动作业或恢复先前抢占的作业时,调度程序依赖于放置模块来分配其 GPU。
- 4)如果一个作业是第一次启动,放置模块首先对其进行剖析——剖析器识别作业特定的特征,例如张量分布中的偏斜,以确定是否合并该作业 。
调度
我们观察到抢占式调度对于实现调度目标来说是必要的。
为什么是二维调度
通过回顾基于时间或大小的启发式方法,我们认为在 GPU 资源有限的集群上调度 DDL 作业时仅考虑一个方面(空间或时间)是不够的。
- 在 SRTF 调度程序中,剩余时间短的大型作业会占用许多 GPU,从而导致许多新提交的小型作业出现不可忽略的排队延迟。
- 如果调度程序是GPU 的数量最小优先SF的,那么大型作业可能会被一连串的小型作业阻塞,即使它们接近完成
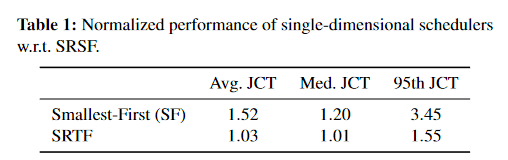
2DAS 二维的获得性基于服务的调度器
2DAS是对传统LAS的扩展,同时考虑了时间和空间,它会赋予任务一个优先级,这个优先级和时间以及空间有关。
而这个优先级函数有不同的情况,当有没有先验知识的时候,即没有任务持续时间的分布的时候,使用LAS算法,如果有先验分布,则使用Gittins索引
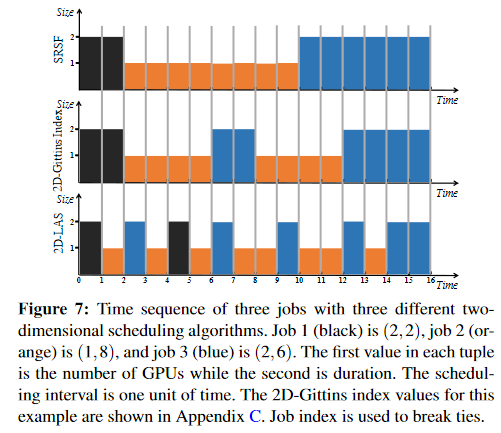
优先级的离散化
使用连续的优先级会导致一系列的抢占和一系列的重启,对于分布式深度学习任务来说,抢占和重启的代价很高,过多的抢占会导致2DAS不可用
为了解决这个问题,基于传统的**多级别反馈队列(MLFQ)**算法实现优先级离散化的框架。即,将原有的一个队列变成K个队列。
- 整体结构确保具有相似 (WJtJ) 值的作业保留在同一队列中。具有高度不同 (WJtJ) 值的作业保持在不同的优先级。
- 使用 LAS 时,同一队列中的作业按其开始时间的 FIFO 顺序进行调度(即,首次调度它们的时间),没有任何 HOL 阻塞的风险。
- Gittins 指数中的服务量 Δ 也是离散化的。对于 Qi 中的作业,Δi 等于 Qhi i,这是 Qi 的上限。当一个作业用完它的所有服务量时,它将被降级到较低优先级的队列。对于 Gittins 索引,同一队列中的作业根据其 Gittins 索引值进行调度。在最后一个队列 QK 中,ΔK 被设置为 ∞。在这种极端情况下,Gittins 索引的表现与 LAS 类似,最后一个队列中的作业按照 FIFO 顺序进行调度。
放置
给定一个任务,需要参数服务器以及Worker,如果有足够的资源,Tiresias需要知道是否在尽可能少的机器中合并一些任务的GPU或者去分发它们,前者在微软的的生产集群中实现,故一个任务即使资源足够也可能被放置在等待队列。本文使用ILP,即整数线性规划来优化这个分配问题。
合并对于任务来说重要吗?
深度学习模型中对于合并敏感的一般都有较大的张量, 原因是模型聚合中的消息大小与模型的结构密切相关。 例如,TensorFlow中的模型由许多张量组成。 每个张量都被包装为单个通信消息。因此,DDL中的消息大小分布取决于模型的张量大小分布。 张量大小通常分布不均匀; 有时存在巨大的张量,其中包含这些模型中的大部分参数。 因此,聚合较大的张量会更严重地受到网络争用的影响,而较小张量的传输往往会相互交错。
利用这个直觉,设计了Tiresias的分析器,用于分析每个模型的偏差程度,再使用放置的算法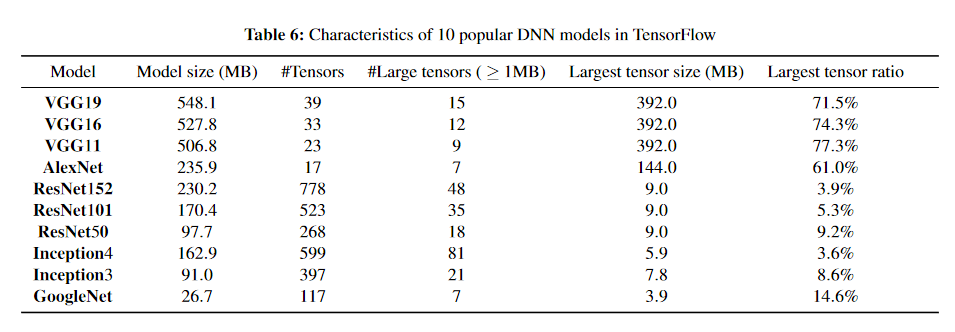
总结
- 与 Apache YARN 的容量调度程序 (YARNCS) 和 Gandiva 相比,Tiresias 旨在最小化平均 JCT。
- 与 Optimus 不同,Tiresias 可以在没有或有部分先验知识的情况下有效地安排工作(表 2)。
- 此外,Tiresias 可以根据 Tiresias 分析器自动捕获的模型结构巧妙地放置 DDL 作业。
实现
中心Master
除了启动新作业和完成现有作业外,master 的一个主要功能是当它们的(GPU)资源被调度程序分配给其他作业时抢占正在运行的作业。
由于 DL 作业的迭代性质,我们不需要将所有数据保存在 GPU 和主内存中以进行作业抢占。
目前,我们使用几乎所有 DL 框架提供的检查点功能来为抢占作业保存最新模型。
当触发抢占时,作业首先被暂停;然后它的首席工作者将它的模型检查点到一个集群范围的共享文件系统。
当调度程序再次恢复暂停的作业时,将在重新启动之前加载其最近的检查点。中央主机还使用放置算法和分析器确定作业的放置。
分布式RDMA监控
由于 RDMA 在 GPU 集群中广泛用于 DDL 作业,我们将分析器实现为可加载库,用于拦截 RDMA ibverbs API。
因此,它可以记录每个服务器上的所有 RDMA 活动,例如建立连接、发送和接收数据。所有相关工作人员和参数服务器的 RDMA 级信息随后在中央分析器中聚合。
基于聚合信息(例如,消息大小和总流量),Tiresias 可以解析给定 DDL 作业的详细模型信息,包括其偏差。
虽然是为 RDMA 网络实现的,但分析器可以通过拦截套接字 API 轻松扩展以支持 TCP/IP 网络。